

Comment déployer les MLT Partie 1: Où vivent vos modèles?
- Legal Transformation
Dans les premiers temps des modèles d'IA de première génération, les fournisseurs de technologie de l'industrie juridique n'ont pas souvent été confrontés à la question suivante, « Où vivent mes modèles? »
L'hypothèse a toujours été que les modèles vivaient là où les données vivaient. Si vous aviez une licence de logiciel eDiscovery sur site, par exemple, les modèles vivaient « localement » dans votre centre de données ou votre instance cloud.
Aujourd'hui, avec les grands modèles linguistiques (LLM), les clients sont confrontés à un nouveau type de technologie, avec des capacités énormes et des défis complexes. Nous détaillons ci-dessous les questions à poser à votre fournisseur et la manière de comprendre ses réponses concernant la qualité et la performance de sa solution ainsi que les implications en matière de sécurité et de confidentialité.
Pourquoi demander maintenant?
La question « Où vit votre modèle? » se pose soudainement car ces modèles, en particulier les LLM, ont dépassé les capacités de calcul dont disposent la plupart des entreprises du classement Fortune 100, sans parler des fournisseurs de solutions eux-mêmes. Par conséquent, très peu d'entreprises disposent des ressources nécessaires pour construire et former des LLM. Des entreprises telles que OpenAI GPT, Anthropic Claude et Google Gemini ont pris en charge ces investissements massifs et mis leurs modèles à disposition via des API. Au cours des deux dernières années, elles ont donné naissance à des milliers de fournisseurs de services qui intègrent ce service API dans leurs solutions. Dans les services juridiques, nous voyons souvent ces itérations dans l'examen des documents, le résumé des documents et l'examen des contrats.
La large disponibilité des services de tiers apporte des avantages significatifs, mais elle soulève également de nouvelles questions que nous n'avions pas rencontrées jusqu'à présent:
- Quelles sont les informations que je partage avec des LLM tiers?
- Mes informations sont-elles stockées et utilisées pour améliorer leurs modèles?
- Ai-je le contrôle de ces modèles et, si ce n'est pas le cas, qui l'a?
La liste des questions ne fait que s'allonger au fur et à mesure que des LLM à code source ouvert deviennent disponibles, ce qui, avec l'infrastructure adéquate, permet de construire des déploiements qui ne dépendent pas du tout de fournisseurs tiers. Dans ce cas, il devient important de comprendre ce que vous gagneriez et sacrifieriez en évitant les solutions qui s'appuient sur des fournisseurs de services tiers.
Comment les gestionnaires du droit d'auteur sont-ils généralement déployés?
Il existe plusieurs options de déploiement pour un service LLM, dont certaines nous sont familières et d'autres ont évolué par nécessité.
Dans une application classique d'IA de première génération, telle que l'examen de contrats ou de documents, qui étaient principalement des tâches de classification, les modèles d'IA étaient suffisamment petits pour vivre avec vos données, que ce soit dans votre propre centre de données ou dans un nuage géré, à l'écart des autres clients:
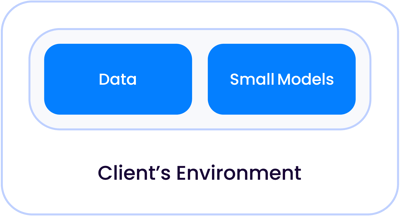
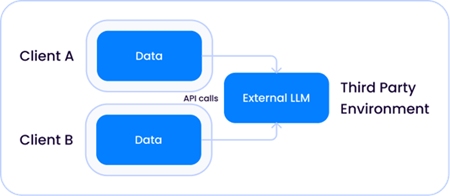
Comme les tailles des modèles ont augmenté de façon exponentielle pour devenir ce que nous appelons aujourd'hui les LLM, il y a deux cas dans lesquels ces modèles peuvent vivre par rapport à vos données.
1. Un modèle tiers partagé hébergé par une société telle qu'Open AI, où le LLM est externe à la fois au fournisseur de la solution et à vos environnements:
2. Un LLM hébergé et déployé directement par votre fournisseur de solutions, dans son environnement en nuage:

(Les fournisseurs de services supportent des coûts de calcul et d'infrastructure importants en hébergeant des LLM et sont donc susceptibles de déployer des LLM en tant que service partagé par leurs clients).
Compte tenu de cet aperçu de la variété des architectures de déploiement qui existent aujourd'hui, il est naturel de se poser la question suivante: « Y a-t-il un risque pour un fournisseur de solutions de s'appuyer sur un service API externe comme OpenAI?
Y a-t-il un risque à ce qu'un fournisseur de solutions s'appuie sur un service d'API externe tel qu'OpenAI?
Comme pour tout, la réponse générale est « Cela dépend » - il faut tenir compte de trois facteurs:
1. La mesure dans laquelle un tiers, comme OpenAI, conserve les données envoyées à son API.
Les fournisseurs de services auront des politiques différentes sur la durée de conservation des données envoyées à leurs API, et ces politiques sont susceptibles de découler des conditions de service avec leurs fournisseurs tiers d'API LLM.
Par exemple, Microsoft a une politique de conservation par défaut de 30 jours pour toutes les données envoyées à son API GPT; cependant, les fournisseurs de solutions peuvent négocier des exemptions à ces conditions, et beaucoup ont obtenu une politique de conservation de zéro jour.
Nous vous recommandons de vous renseigner directement auprès de votre fournisseur de solutions sur la politique de conservation qu'il a mise en place avec le fournisseur de services API tiers et, si nécessaire, de l'optimiser pour votre organisation.
Il est important de faire la distinction entre la conservation et l'utilisation de vos données. La conservation n'implique pas que le tiers puisse utiliser vos données pour entraîner ses modèles - la plupart des contrats de service prévoient que le tiers ne peut pas utiliser vos données.
2. La nature et la quantité des données envoyées.
La nature et la quantité des données dépendent entièrement de l'application. Par exemple, une solution qui n'utilise une API externe que pour des données publiques, telles que les dépôts de documents auprès des tribunaux, présenterait un profil de risque différent de celui d'une solution qui envoie les données de recherche d'un client à l'API. Si l'on va plus loin, différents fournisseurs de solutions peuvent envoyer des volumes très différents de données sensibles à l'API dans le cadre d'applications de recherche de preuves. Par exemple, les solutions qui répondent à des questions ciblées sur des données n'envoient généralement qu'une douzaine d'extraits de documents récupérés par un moteur de recherche à une API externe. En revanche, les solutions qui s'appuient sur l'API d'un tiers pour classer les documents enverraient des millions de documents.
3. Conditions d'utilisation des tiers sur ce qu'ils peuvent faire avec vos données.
Enfin, il est important de comprendre qu'avec l'augmentation du nombre de fournisseurs d'API tiers pour les LLM, tous ne sont pas égaux quant à ce qu'ils peuvent faire avec les données qui leur sont envoyées. Par exemple, l'API GPT-4 fournie directement par OpenAI peut explicitement utiliser vos données pour améliorer ses modèles, alors que le même modèle GPT-4 fourni par Microsoft Azure ne le peut pas. Il est important de demander à votre fournisseur de solutions quelles sont les conditions d'utilisation de son service API externe et ce qu'il peut ou ne peut pas faire avec vos données.
Qu'en est-il des fournisseurs de solutions qui déploient leurs propres modèles LLM? Y a-t-il des risques?
Lorsque le fournisseur de solutions déploie un LLM (généralement basé sur l'un des modèles open-source disponibles, tels que Llama-3), il a un contrôle direct sur la conservation et l'utilisation des données. Comme indiqué précédemment, un LLM déployé par un fournisseur de solutions nécessite souvent de lourdes ressources de calcul - et des dépenses financières importantes - et, par conséquent, une architecture très probablement partagée:
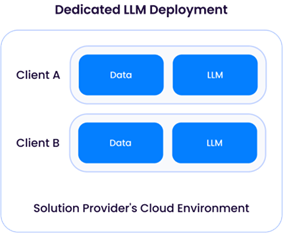
Un « déploiement LLM dédié » exige d'un fournisseur de solutions qu'il fournisse des ressources informatiques (CPU/GPU/mémoire) à un seul client. Cela implique la location de ressources GPU suffisantes auprès d'un fournisseur de services en nuage, ce qui entraîne des coûts d'exploitation plus élevés. L'avantage de cette approche est la flexibilité dont dispose le fournisseur de solutions pour adapter le LLM à chaque client en utilisant ses données pour améliorer le modèle sans les mélanger avec les données d'autres clients:
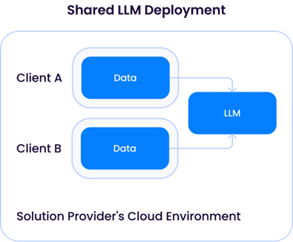
Le modèle LLM partagé, cependant, soulèverait des problèmes similaires à ceux de l'exemple du fournisseur de services LLM tiers décrit plus haut. Bien que cela puisse sembler inquiétant à première vue, tant que les données de différents clients ne sont pas utilisées pour mettre à jour le LLM sous-jacent, l'architecture serait très similaire à celle d'un service d'API tiers comme OpenAI et (au moins théoriquement) aurait le même profil de risque.
Pour en savoir plus sur l'approche d'Epiq en matière de fourniture de solutions d'IA et sur son engagement en faveur d'un développement responsable de l'IA.
 Igor Labutov, vice-président, Epiq AI Labs
Igor Labutov, vice-président, Epiq AI Labs
Igor Labutov est vice-président d'Epiq et codirige Epiq AI Labs. Igor est un informaticien qui s'intéresse particulièrement au développement d'algorithmes d'apprentissage automatique qui apprennent à partir d'une supervision humaine naturelle, telle que le langage naturel. Il a plus de 10 ans d'expérience dans le domaine de l'intelligence artificielle et de l'apprentissage automatique. M. Labutov a obtenu son doctorat à Cornell et a été chercheur post-doctoral à Carnegie Mellon, où il a mené des recherches pionnières à l'intersection de l'intelligence artificielle centrée sur l'homme et de l'apprentissage automatique. Avant de rejoindre Epiq, M. Labutov a cofondé LAER AI, où il a appliqué ses recherches au développement d'une technologie transformatrice pour l'industrie juridique.
Le contenu de cet article est destiné à transmettre des informations générales uniquement et non à fournir des conseils ou des avis juridiques.
Cet article est destiné à fournir des informations générales et non des conseils ou des avis juridiques.