
Angle

Como implantar LLMs - Parte 1: Onde estão seus modelos?
- Legal Transformation
Nos primórdios dos modelos de IA de primeira geração, os fornecedores de tecnologia do setor jurídico não se deparavam com frequência com a pergunta: “Onde estão meus modelos?”
O pressuposto sempre foi que os modelos vivem onde os dados vivem. Se você tivesse uma licença de software de eDiscovery no local, por exemplo, os modelos residiam “localmente” em seu data center ou instância de nuvem.
Agora, com os modelos de linguagem grande (LLMs), os clientes enfrentam um novo tipo de tecnologia com enormes recursos e desafios complexos. Abaixo, detalhamos as perguntas que devem ser feitas ao seu provedor e como entender suas respostas com relação à qualidade e ao desempenho da solução e às implicações de segurança e privacidade.
Por que perguntar agora?
“Onde fica o seu modelo?” é uma pergunta que, de repente, passou a prevalecer, porque esses modelos, especificamente os LLMs, ultrapassaram os recursos computacionais disponíveis para a maioria das empresas da Fortune 100, sem falar nos próprios provedores de soluções. Como resultado, pouquíssimas empresas têm os recursos para criar e treinar LLMs. Empresas como a OpenAI GPT, Anthropic Claude e Google Gemini assumiram esses investimentos maciços e disponibilizaram seus modelos por meio de APIs. Nos últimos dois anos, elas geraram milhares de provedores de serviços que empacotam esse serviço de API como parte de suas soluções. Nos serviços jurídicos, vemos com frequência essas iterações na revisão de documentos, resumo de documentos e revisão de contratos.
A ampla disponibilidade de serviços de terceiros traz vantagens significativas, mas também levanta novas questões que não encontramos anteriormente:
- Quais informações estou compartilhando com LLMs de terceiros?
- Minhas informações são armazenadas e usadas para aprimorar seus modelos?
- Eu tenho controle sobre esses modelos e, se não tiver, quem tem?
A lista de perguntas só aumenta à medida que mais LLMs de código aberto se tornam disponíveis, o que, com a infraestrutura certa, possibilita a criação de implementações que não dependem de provedores terceirizados. Nesse caso, torna-se importante entender o que você ganharia e o que sacrificaria ao evitar soluções que dependem de provedores de serviços terceirizados.
Como os LLMs são normalmente empregados?
Há várias opções de implementação para um serviço de LLM, algumas das quais já conhecemos e outras que evoluíram por necessidade.
Em um aplicativo clássico de IA de primeira geração, como revisão de contratos ou revisão de documentos, que eram principalmente tarefas de classificação, os modelos de IA eram pequenos o suficiente para conviver com seus dados, seja em seu próprio data center ou em uma nuvem gerenciada, separados de outros clientes:
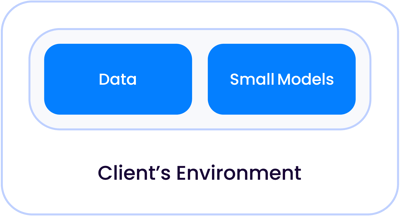
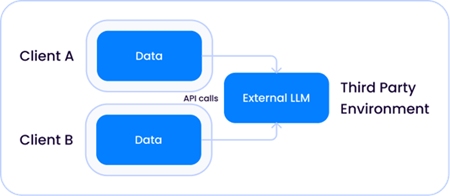
Como os tamanhos dos modelos cresceram exponencialmente para se tornarem o que chamamos hoje de LLMs, há duas instâncias em que esses modelos podem viver em relação aos seus dados.
1. Um modelo compartilhado de terceiros hospedado por uma empresa como a Open AI, em que o LLM é externo ao provedor de soluções e aos seus ambientes:
2. Um LLM hospedado e implementado diretamente pelo seu provedor de soluções, em seu ambiente de nuvem:

(Os provedores de serviços incorrem em custos significativos de computação e infraestrutura para hospedar LLMs e, portanto, é provável que implantem LLMs como um serviço compartilhado por seus clientes).
Considerando essa cartilha sobre a variedade de arquiteturas de implementação existentes atualmente, é natural perguntar:
Existe algum risco no fato de um provedor de soluções depender de um serviço de API externo como o OpenAI?
Como em tudo, a resposta geral é “Depende” - considere três fatores:
1. A extensão em que um terceiro, como a OpenAI, retém os dados enviados à sua API.
Os provedores de serviços terão políticas diferentes sobre o tempo de retenção dos dados enviados às suas APIs, e essas políticas provavelmente fluirão dos termos de serviço com seus provedores de API LLM terceirizados.
Por exemplo, a Microsoft tem uma política padrão de retenção de 30 dias para todos os dados enviados à sua API GPT; no entanto, os provedores de soluções podem negociar isenções a esses termos e muitos obtiveram uma política de retenção de dia zero. Recomendamos que você pergunte diretamente ao seu provedor de soluções sobre a política de retenção que ele tem em vigor com o provedor de serviços de API de terceiros e, se necessário, otimize-a para a sua organização.
É importante distinguir entre retenção e uso de seus dados. A retenção não implica que o terceiro possa usar seus dados para treinar os modelos dele - na maioria dos contratos de serviço, o terceiro não pode usar seus dados.
2. A natureza e a quantidade dos dados enviados.
A natureza e a quantidade dos dados são totalmente específicas do aplicativo. Por exemplo, uma solução que usa apenas uma API externa em dados públicos, como registros públicos de tribunais, apresentaria um perfil de risco diferente de uma solução que envia os dados de descoberta de um cliente para a API. Mais detalhadamente, diferentes provedores de soluções podem enviar volumes drasticamente diferentes de dados confidenciais para a API em aplicativos de descoberta. Por exemplo, as soluções que realizam perguntas direcionadas de dados normalmente enviariam no máximo uma dúzia de trechos de documentos recuperados por meio de um mecanismo de pesquisa para uma API externa. Em contrapartida, as soluções que dependem da API de terceiros para classificar documentos enviariam milhões de documentos.
3. Termos de serviço de terceiros sobre o que eles podem fazer com seus dados.
Por fim, é importante entender que, à medida que o número de provedores de API de terceiros para LLMs aumenta, nem todos são iguais em relação ao que podem fazer com os dados enviados a eles. Por exemplo, a API GPT-4 fornecida diretamente pela OpenAI pode usar explicitamente seus dados para melhorar os modelos, enquanto o mesmo modelo GPT-4 fornecido pelo Microsoft Azure não pode. É importante perguntar ao seu provedor de soluções sobre os termos de serviço do serviço de API externo e o que especificamente ele pode ou não fazer com seus dados.
E quanto aos provedores de soluções que implementam seus próprios modelos de LLM? Há riscos nisso?
Quando o provedor de soluções implementa um LLM (normalmente baseado em um dos modelos de código aberto disponíveis, como o Llama-3), ele tem controle direto sobre a retenção e o uso dos dados. Conforme mencionado anteriormente, um LLM implantado por um provedor de soluções geralmente requer recursos computacionais pesados - e gastos financeiros significativos - e, portanto, uma arquitetura provavelmente compartilhada:
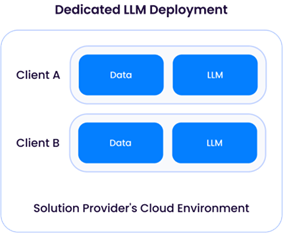
Uma “Dedicated LLM Deployment” exige que um provedor de soluções provisione recursos de computação (CPU/GPU/memória) para apenas um cliente. Isso implicaria o aluguel de recursos de GPU suficientes de um provedor de nuvem, resultando em custos operacionais mais altos. A vantagem dessa abordagem é a flexibilidade do provedor de soluções para personalizar o LLM para cada cliente, usando seus dados para aprimorar o modelo sem misturá-los com dados de outros clientes:
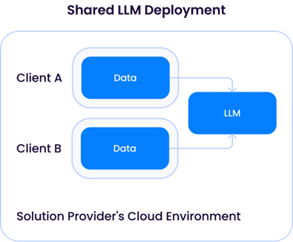
O modelo de LLM compartilhado, no entanto, levantaria problemas semelhantes aos da instância de provedor de serviços de LLM de terceiros descrita anteriormente. Embora possa parecer preocupante à primeira vista, desde que os dados de diferentes clientes não sejam usados para atualizar o LLM subjacente, a arquitetura seria muito semelhante à de um serviço de API de terceiros como o OpenAI e (pelo menos teoricamente) teria o mesmo perfil de risco.
Saiba mais sobre a abordagem da Epiq para fornecer soluções de IA e o compromisso com o desenvolvimento responsável de IA.
 Igor Labutov, vice-presidente, Epiq AI Labs
Igor Labutov, vice-presidente, Epiq AI Labs
Igor Labutov é vice-presidente da Epiq e co-lidera o Epiq AI Labs. Igor é um cientista da computação com grande interesse no desenvolvimento de algoritmos de aprendizado de máquina que aprendem com a supervisão humana natural, como a linguagem natural. Ele tem mais de 10 anos de experiência em pesquisa em Inteligência Artificial e Aprendizado de Máquina. Labutov obteve seu Ph.D. em Cornell e foi pesquisador de pós-doutorado na Carnegie Mellon, onde realizou pesquisas pioneiras na interseção de IA centrada no ser humano e aprendizado de máquina. Antes de ingressar na Epiq, Labutov foi cofundador da LAER AI, onde aplicou sua pesquisa para desenvolver tecnologia transformadora para o setor jurídico.
O conteúdo deste artigo é destinado apenas a fornecer informações gerais e não a oferecer aconselhamento ou opiniões jurídicas.