
Angle

Seu modelo não está falhando - seus dados é que estão
- 3 Minutes
Desempenho do modelo: Expectativa vs. Realidade
Qual é o seu primeiro instinto quando seu modelo TAR tem um desempenho ruim em um conjunto de controle?
Uma visão comum é que mais dados de treinamento (leia-se: mais esforço de revisão) ajudariam a levar o desempenho em termos de Recall e Precisão para onde você deseja que ele esteja - e com dinheiro e tempo suficientes, próximo de 100%.
Infelizmente, podem ser necessárias centenas de horas de revisão desperdiçadas até que se perceba que o desempenho do modelo está se limitando a um número longe do ideal.
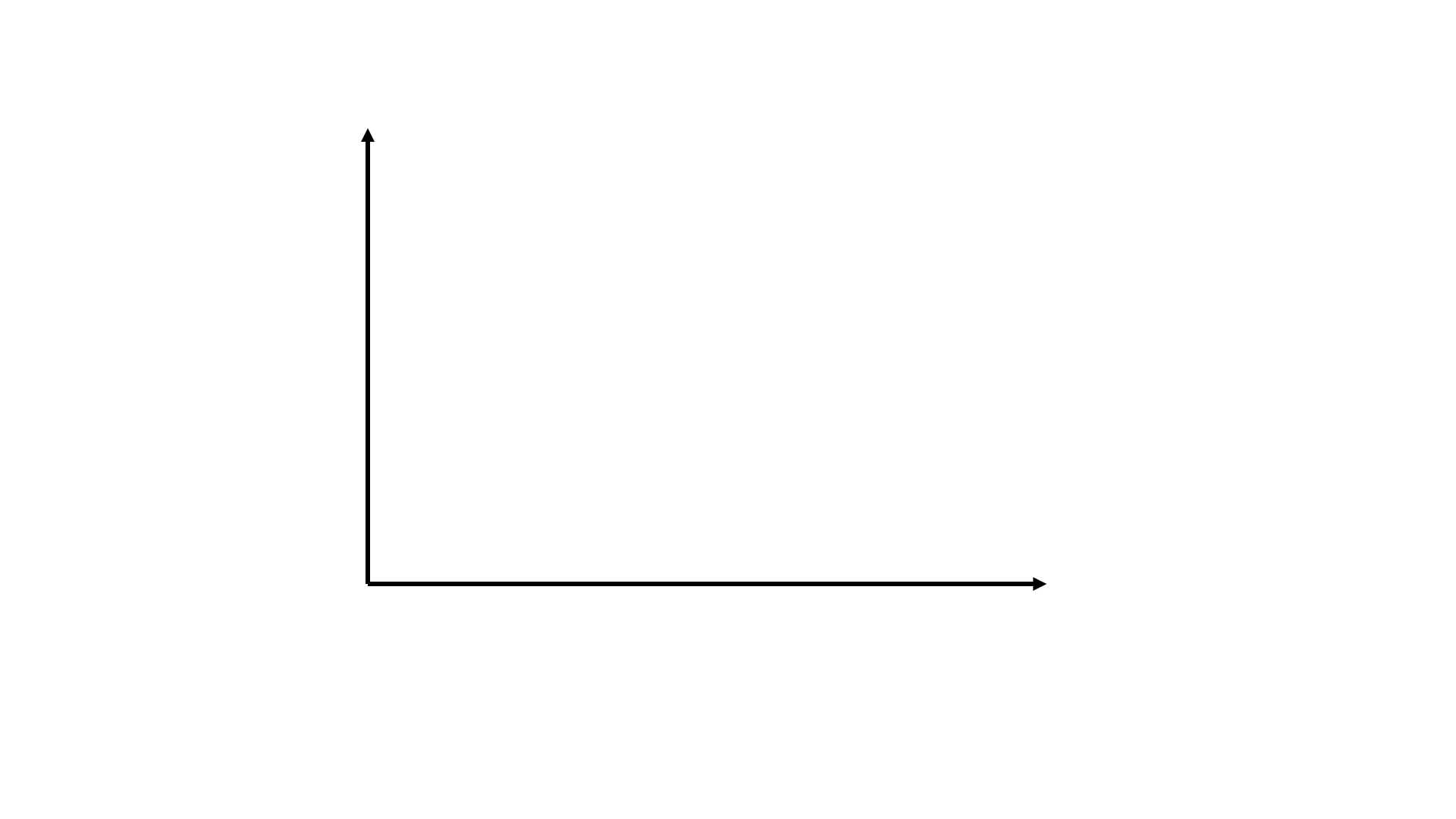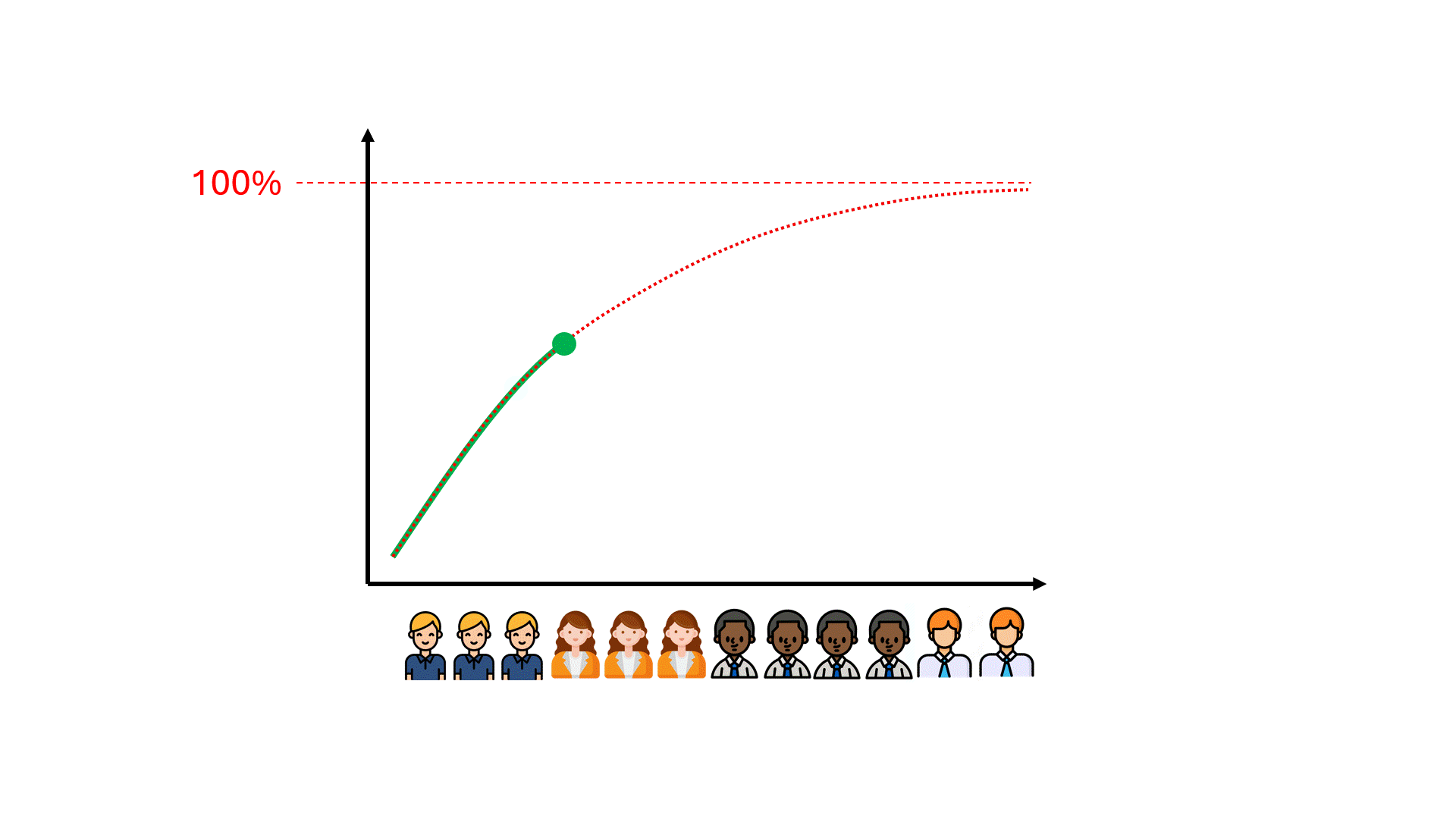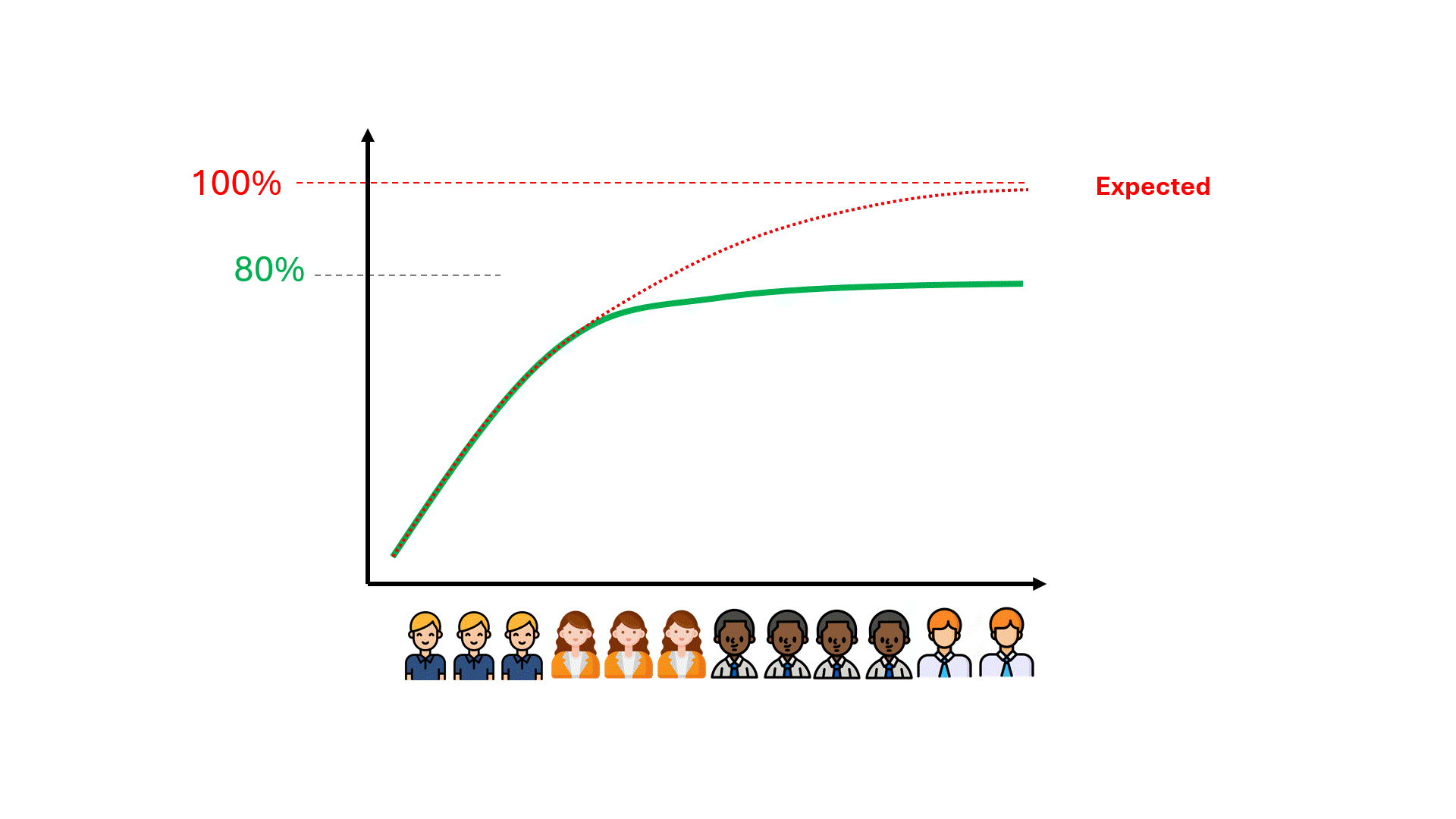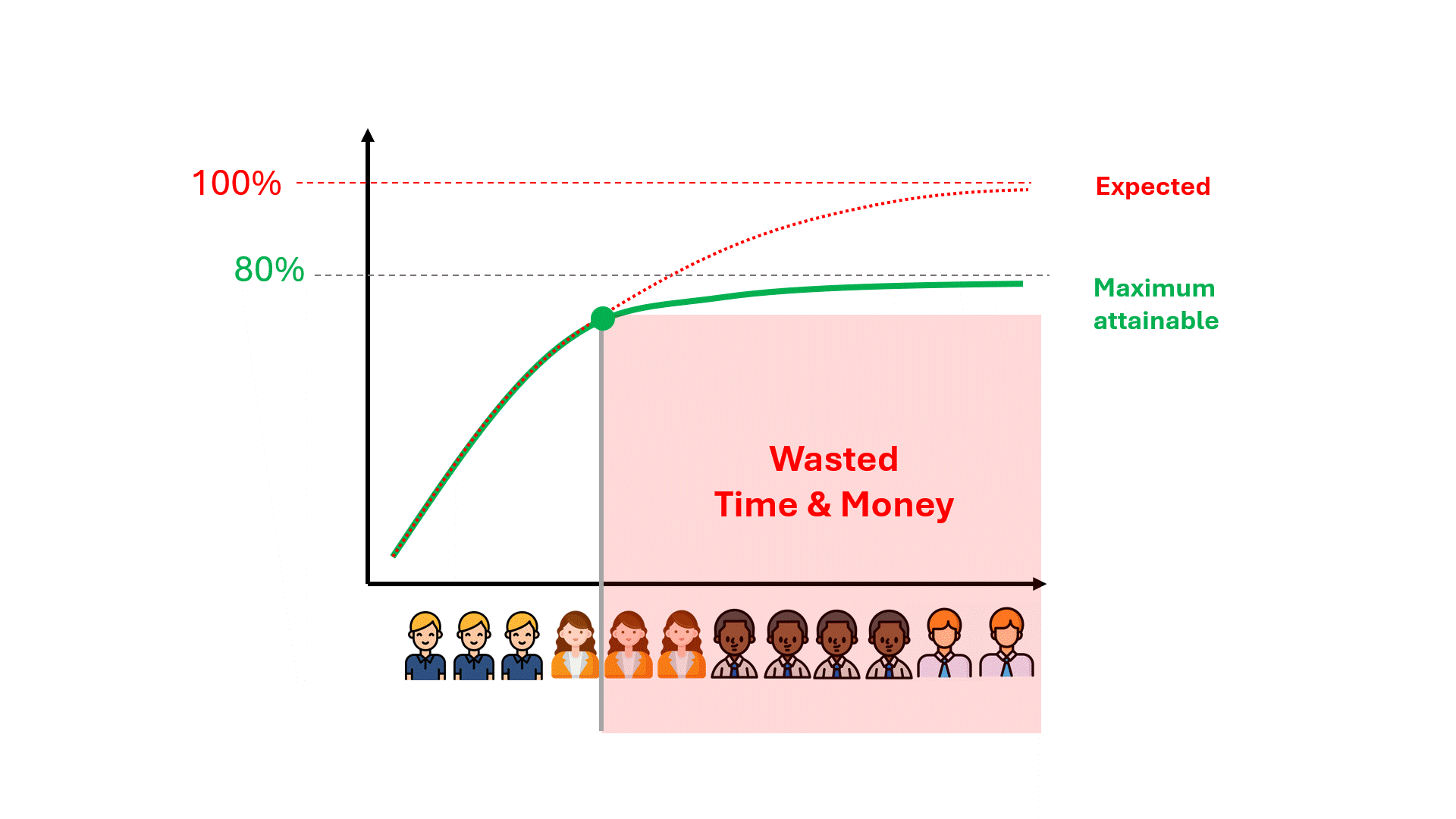
Podemos prever o limite máximo do desempenho do modelo, o que pode nos poupar tempo, dinheiro e expectativas frustradas?
O teto de desempenho já está codificado em seus dados
Os dados codificam certos aspectos sobre o desempenho futuro de qualquer modelo. Um desses aspectos é o teto de desempenho para métricas como precisão e recuperação. Seja o TAR tradicional ou o GPT8, você pode pré-computar os limites de precisão e recuperação, independentemente do modelo utilizado, usando os dados que já possui.
Quando dizemos que os dados já codificam o limite fundamental do desempenho do seu modelo, de quais dados estamos falando - dados de treinamento ou de teste (ou seja, conjunto de controle)?
A realidade é que são ambos, mas neste artigo, vamos nos concentrar no conjunto de controle por dois motivos principais:
-
O conjunto de controle é totalmente independente de modelo.
-
É possível, por meio de matemática simples, calcular os limites máximos de desempenho.
-
Em outras palavras, ao analisar as estatísticas do seu conjunto de controle, podemos deduzir o melhor desempenho para qualquer modelo, inclusive os que não existem atualmente.
O que há nos dados que leva a limites máximos de desempenho?
Embora possa haver problemas com os dados originais (por exemplo, texto mal extraído), estamos falando de tags de revisão criadas por revisores humanos neste artigo. Como se vê, os problemas com os dados que levam a tetos de desempenho se resumem à natureza da revisão humana.
É totalmente suficiente conhecer apenas uma característica de cada avaliador para prever o teto de desempenho de qualquer modelo. Essa característica é o grau de liberalismo ou conservadorismo na aplicação das tags de revisão. Quantitativamente, isso se reflete em sua taxa de resposta ou na riqueza dos dados que geram.

Para ilustrar por que isso é um determinante crítico do teto de desempenho, usaremos dois revisores prototípicos: um revisor liberal que é generoso ao distribuir a tag responsiva ao classificar documentos e um revisor conservador que é particularmente seletivo na marcação de documentos. Na realidade, os revisores estão em um espectro em termos de como marcam, mas a ilustração dos dois extremos ajudará a explicar por que esse fenômeno leva a um limite de desempenho.
Experimento mental nº 1
Para entender a raiz do problema, vamos dar uma olhada em um exemplo muito simples.
Imagine que os revisores conservadores e liberais treinaram seus respectivos modelos apenas com suas tags.
Em seguida, suponha que cada modelo tenha sido avaliado em conjuntos de controle compostos apenas pelas tags do respectivo revisor.
Abaixo está uma visualização simples desse processo. Para fins de ilustração, o revisor conservador tem uma taxa de resposta de 10%, e o revisor liberal tem uma taxa de resposta de 20%.
A questão é: qual é o melhor desempenho possível, ou seja, o teto de desempenho de cada modelo para cada avaliador?
Se eliminarmos os erros ou a autoconsistência de cada avaliador, o melhor desempenho possível em cada conjunto de controle seria, obviamente, 100% (100% de recuperação e 100% de precisão):

Experimento mental n° 2
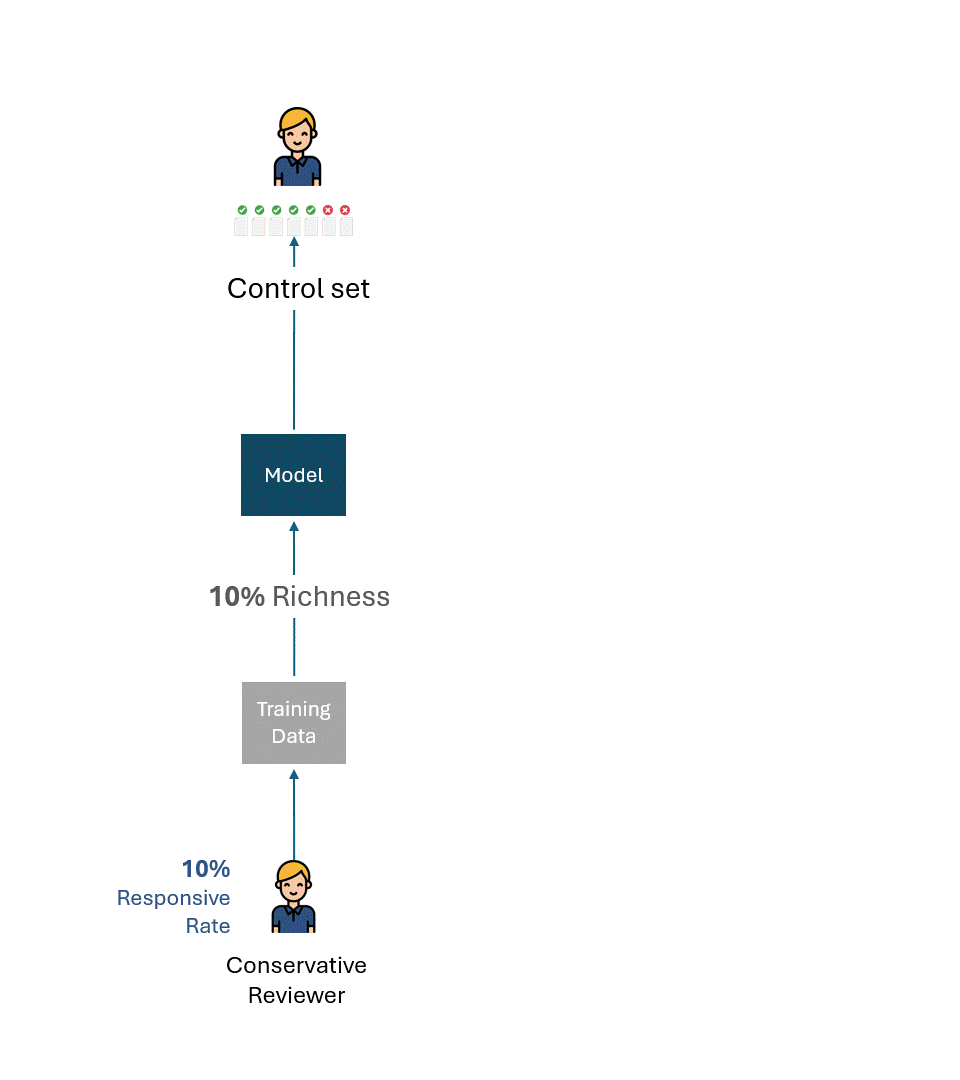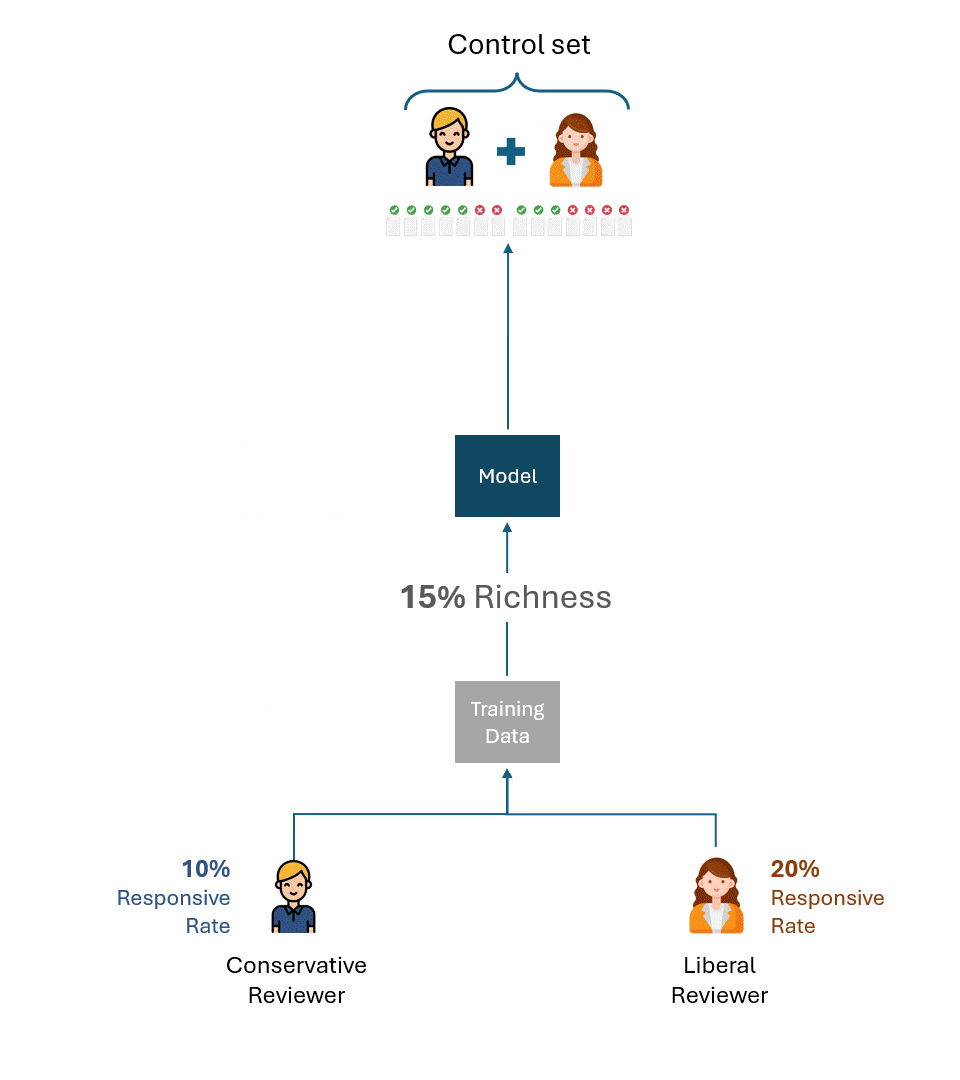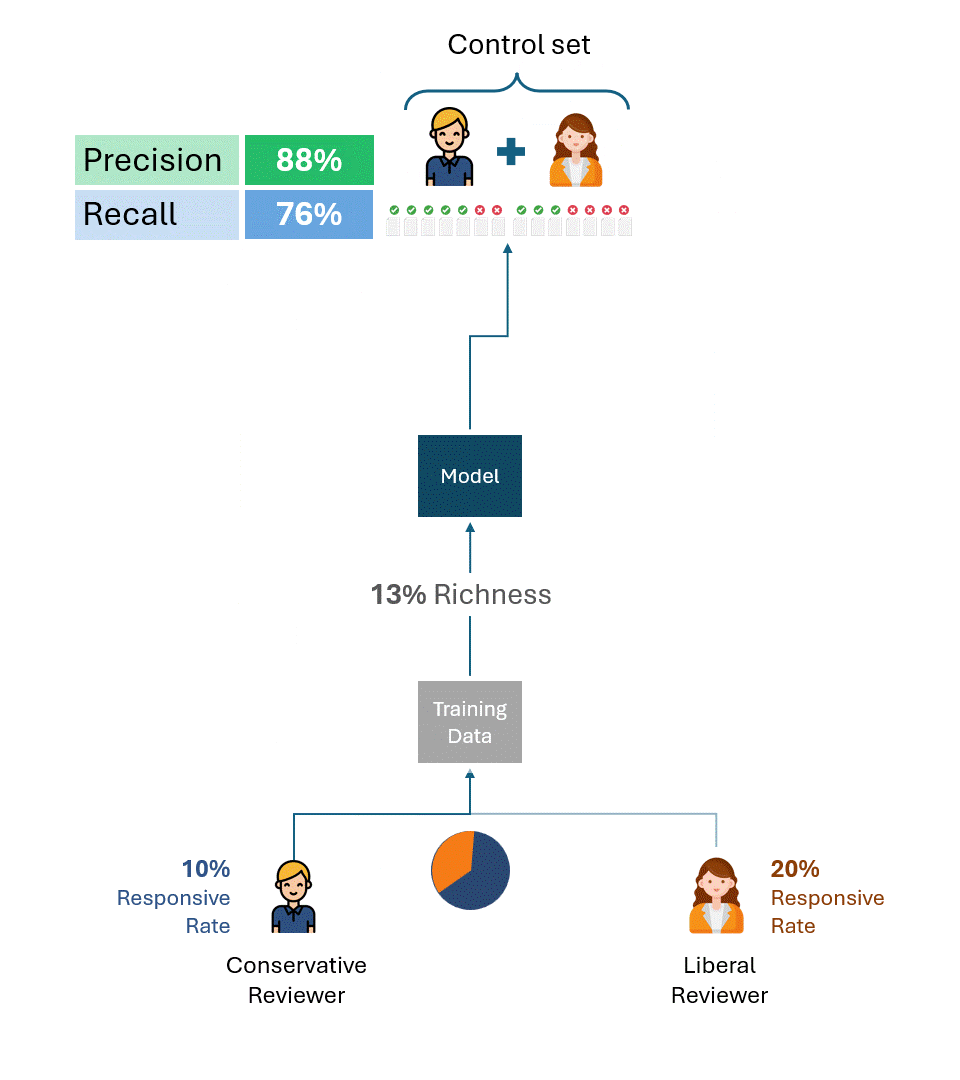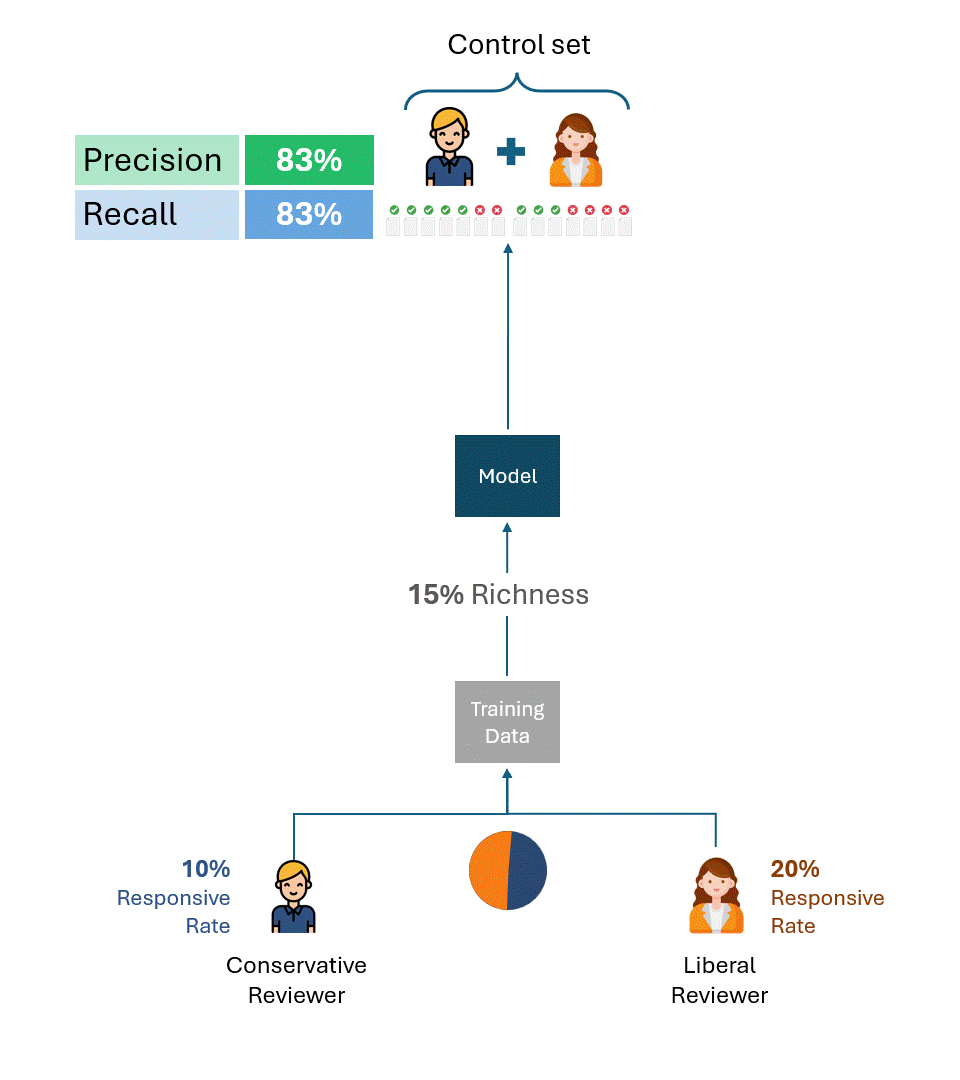
Agora, vamos imaginar uma situação ligeiramente modificada: o conjunto de controle para o modelo treinado pelo revisor conservador foi criado pelo revisor liberal e vice-versa. Em outras palavras, um revisor diferente daquele que treinou o modelo criou o conjunto de controle.
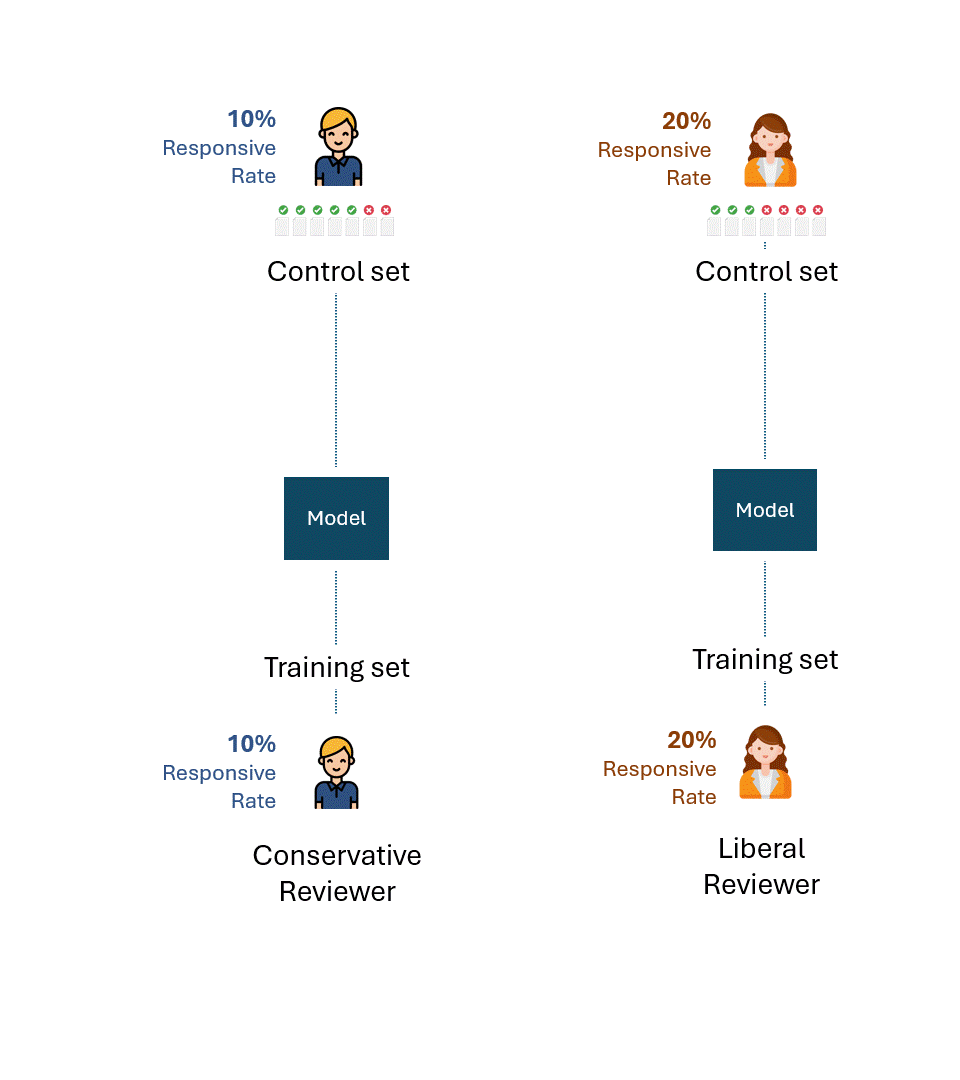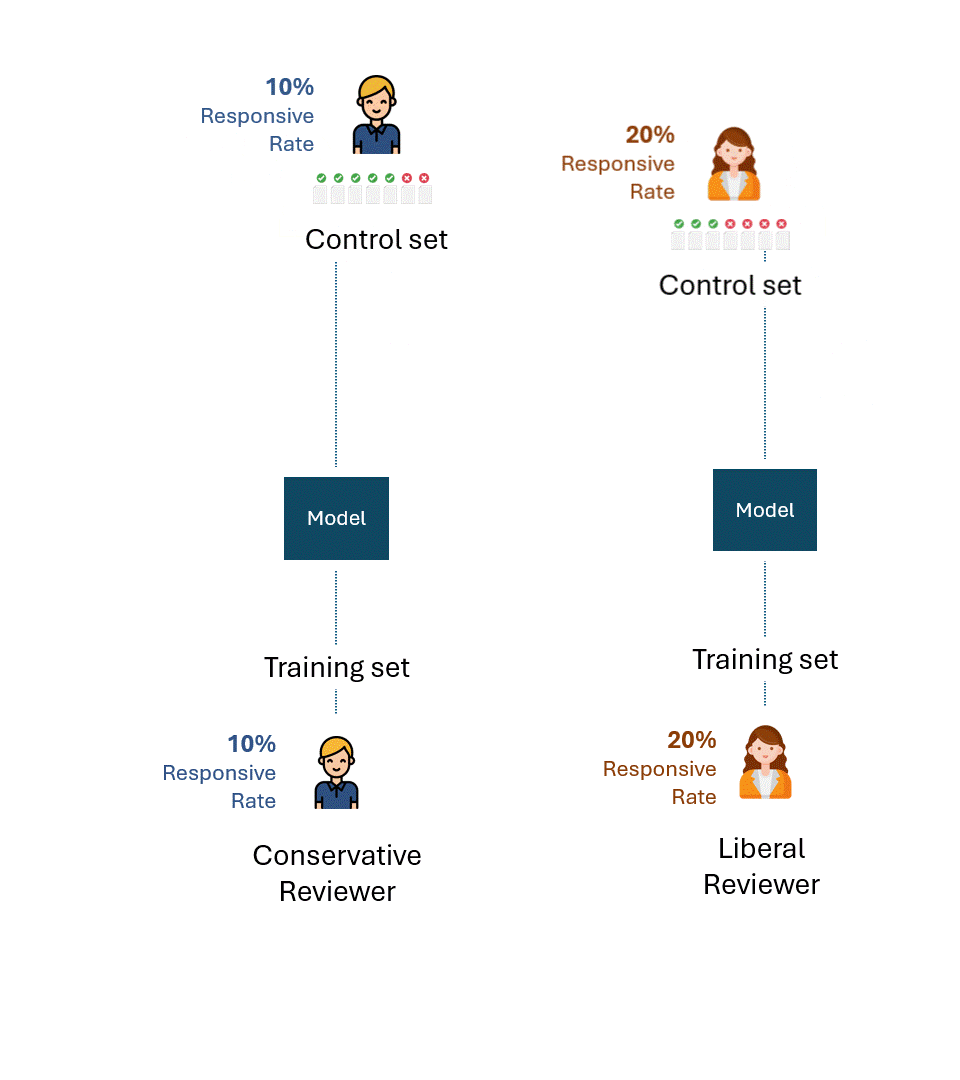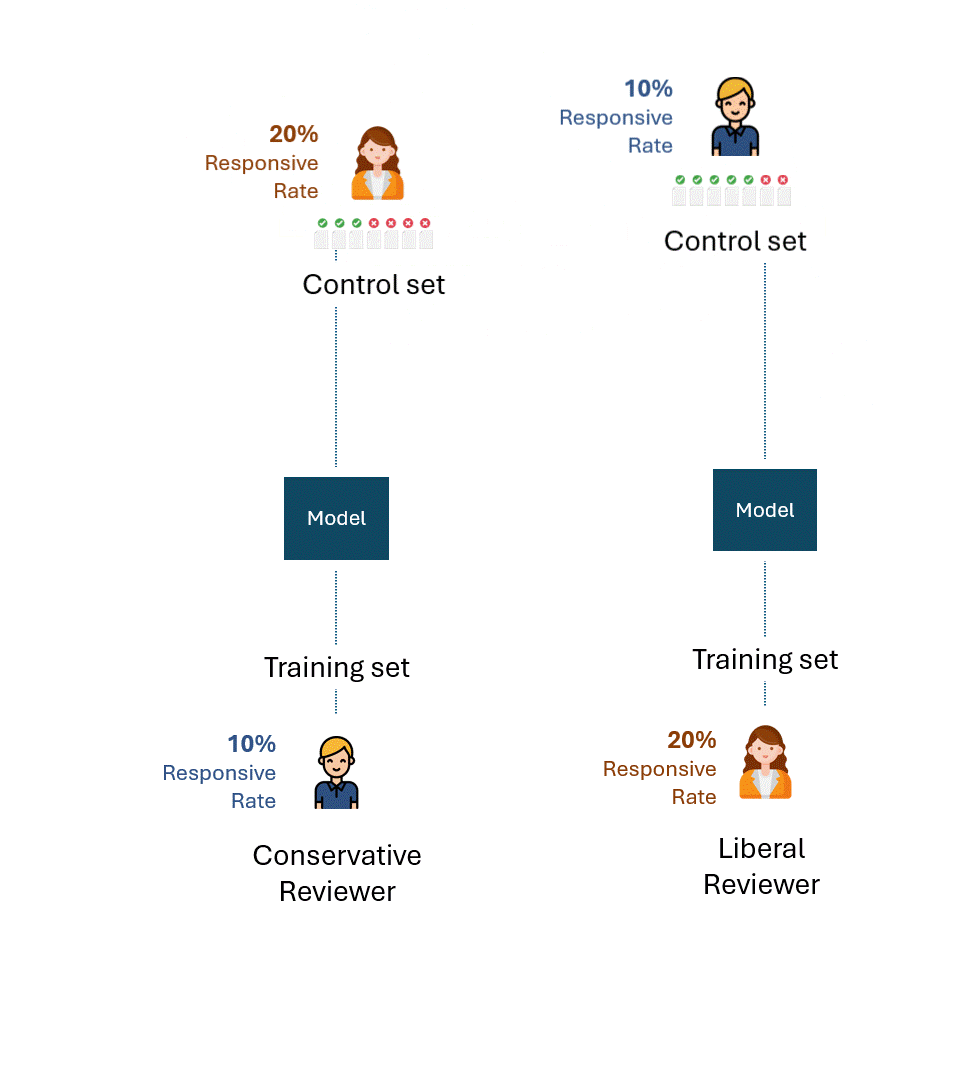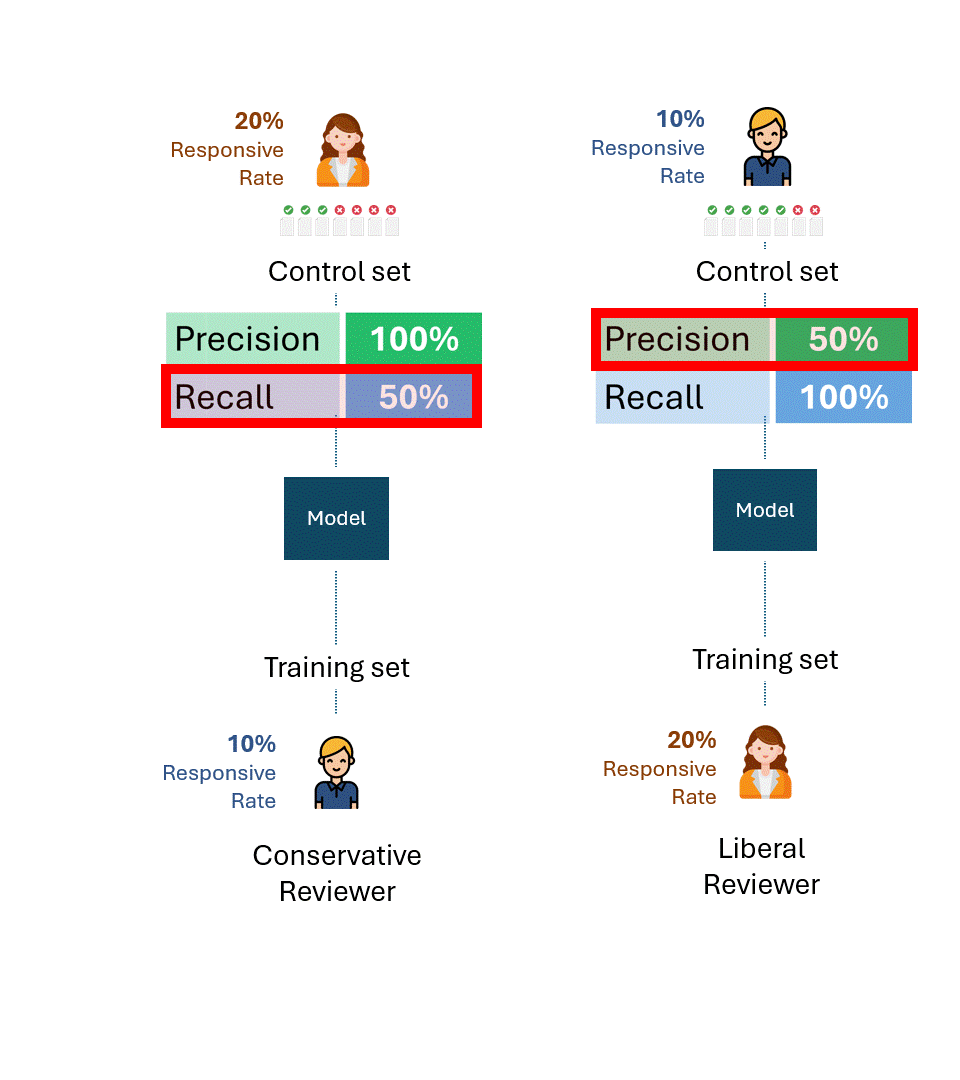
Qual é o melhor desempenho teórico em cada conjunto de controle agora?
Mesmo que um revisor liberal que criasse o conjunto de controle com uma taxa de resposta de 20% e um revisor conservador com uma taxa de resposta de 10% fossem consistentes ao máximo, eles só marcariam metade deles como resposta, uma taxa de recall de 50%.
Pense nas implicações desse fato por um momento. Não há nenhuma quantidade de treinamento que o revisor conservador possa fazer para aumentar essa taxa de recuperação. Se o revisor que treina o modelo e o testa (ou seja, por meio do conjunto de controle) tiver uma disparidade fundamental em sua taxa de resposta, o desempenho não poderá melhorar além de 50%.
O que isso significa na prática?
Os exemplos acima são úteis para ilustrar a causa principal do problema. Na prática, porém, vários revisores criam os dados de treinamento e os conjuntos de controle, sendo que os revisores geralmente são representados em proporções variadas, inclusive entre os dados de treinamento e os conjuntos de controle. Embora isso complique a fórmula para calcular o teto de desempenho, não altera o resultado fundamental:
Desde que o conjunto de controle contenha tags de avaliadores com diferentes taxas de resposta, existirá um teto de desempenho que é completamente independente do modelo.
Isso será válido independentemente de como os dados de treinamento foram criados, seja por apenas um dos avaliadores (liberal ou conservador) ou por alguma combinação proporcional dos dois. O teto de desempenho é determinado puramente pela disparidade na taxa de resposta dos avaliadores somente no conjunto de controle.
Abaixo está um exemplo que ilustra os limites máximos de desempenho de modelos treinados usando proporções variáveis de dados de treinamento de revisores conservadores e liberais. Como você pode ver, em nenhum cenário é possível atingir 100% de desempenho.

Igor Labutov, vice-presidente, Epiq AI Labs
Igor Labutov é vice-presidente da Epiq e co-líder do Epiq AI Labs. Igor é um cientista da computação com grande interesse no desenvolvimento de algoritmos de aprendizado de máquina que aprendem com a supervisão humana natural, como a linguagem natural. Ele tem mais de 10 anos de experiência em pesquisa em Inteligência Artificial e Aprendizado de Máquina. Labutov obteve seu Ph.D. em Cornell e foi pesquisador de pós-doutorado na Carnegie Mellon, onde realizou pesquisas pioneiras na interseção de IA centrada no ser humano e aprendizado de máquina. Antes de ingressar na Epiq, Labutov foi cofundador da LAER AI, onde aplicou sua pesquisa para desenvolver tecnologia transformadora para o setor jurídico.
O conteúdo deste artigo é destinado apenas a fornecer informações gerais e não a oferecer aconselhamento ou opiniões jurídicas.