
Angle

あなたのモデルが失敗しているのではない - あなたのデータが失敗しているのだ
- 3 分
モデルのパフォーマンス 期待と現実
TARモデルがコントロールセットで低いパフォーマンスを示したとき、あなたは最初に何を感じるでしょうか?
一般的に言われているのは、トレーニングデータを増やせば(つまりレビューの手間を増やせば)、RecallとPrecisionのパフォーマンスを望むところまで、つまり十分なお金と時間があれば100%に近づけることができるということです。
残念ながら、モデルの性能が理想からかけ離れた数値で頭打ちになっていることに気づくまでには、何百時間もの無駄なレビュー時間がかかるかもしれません。
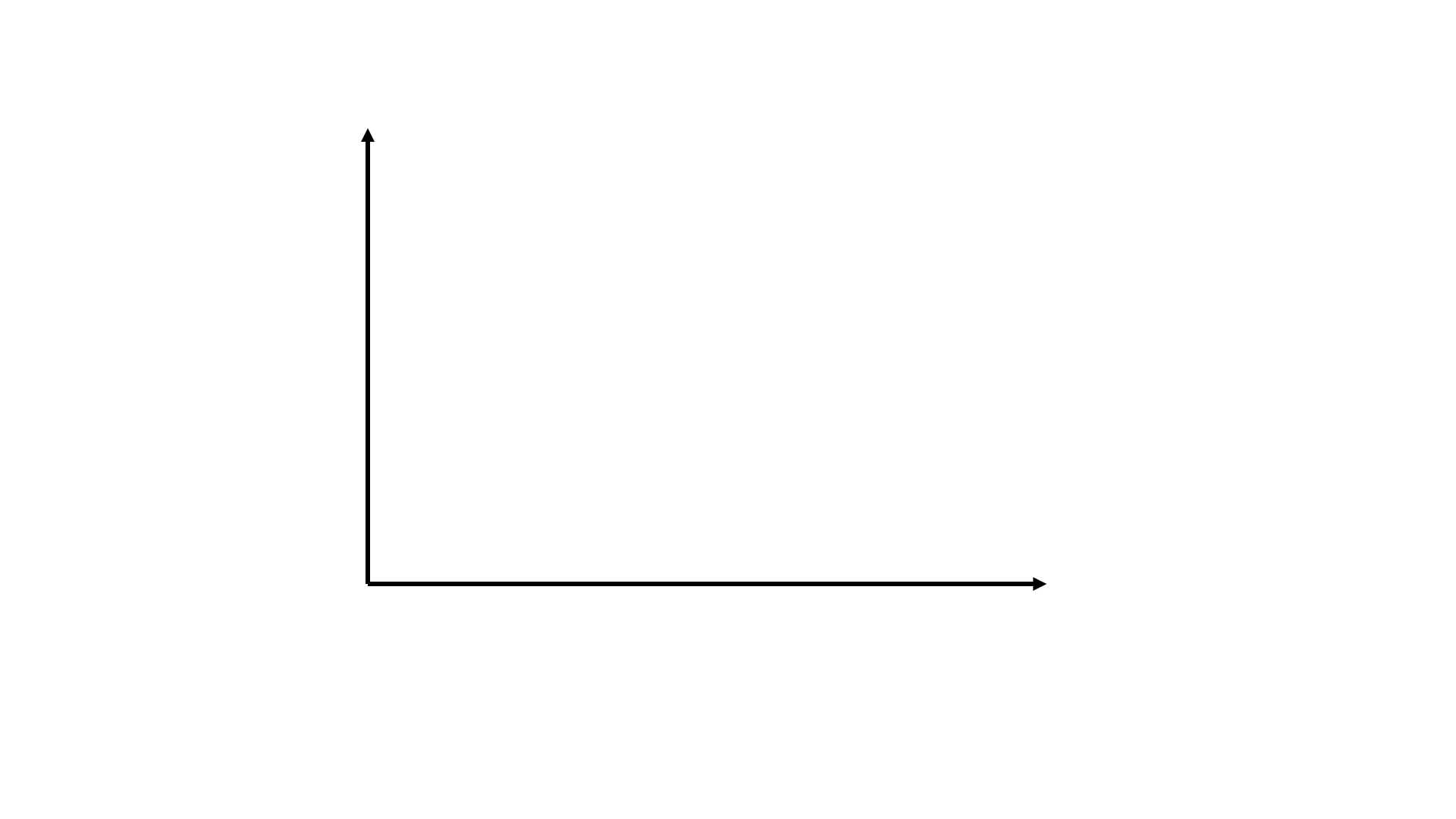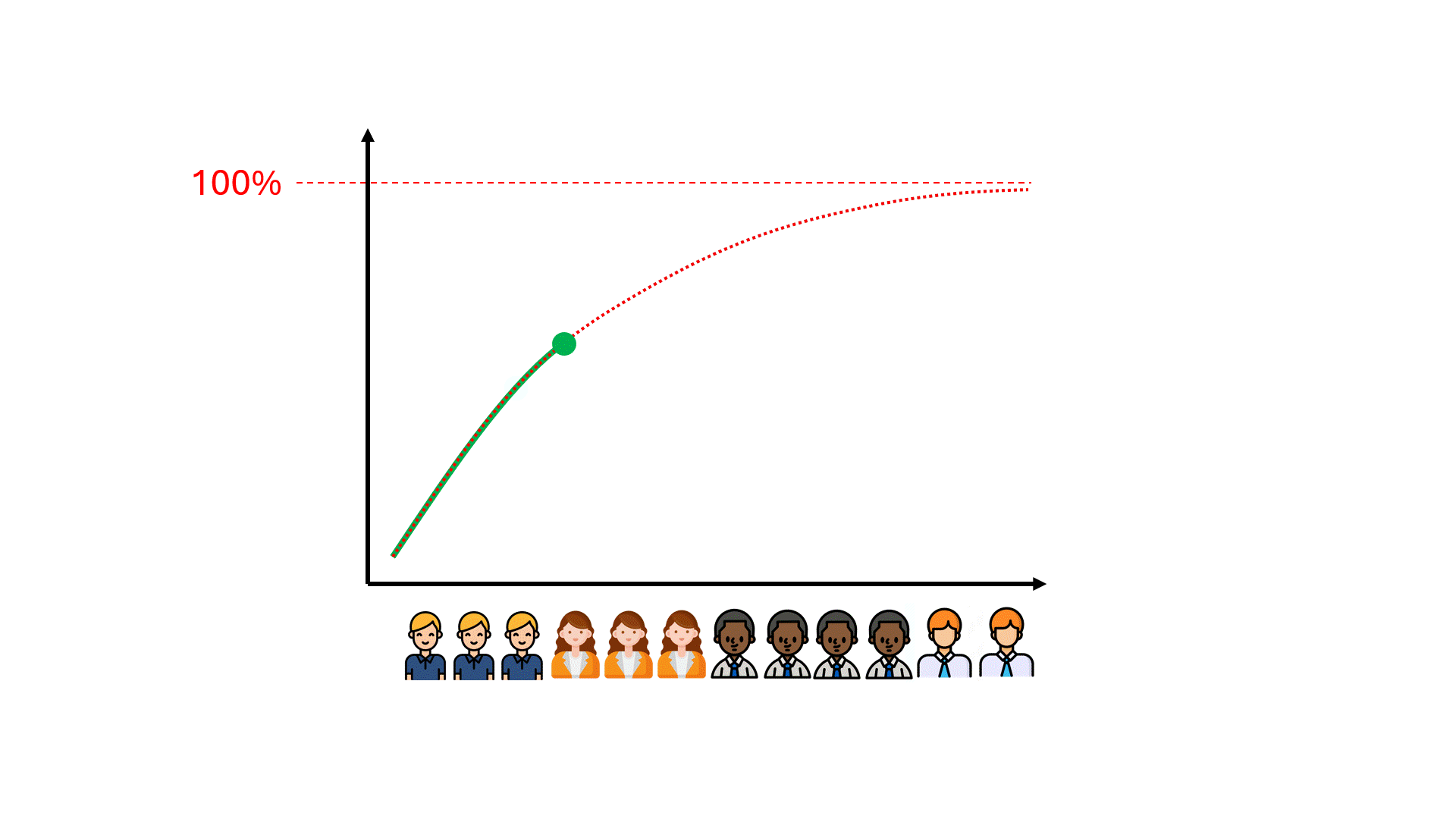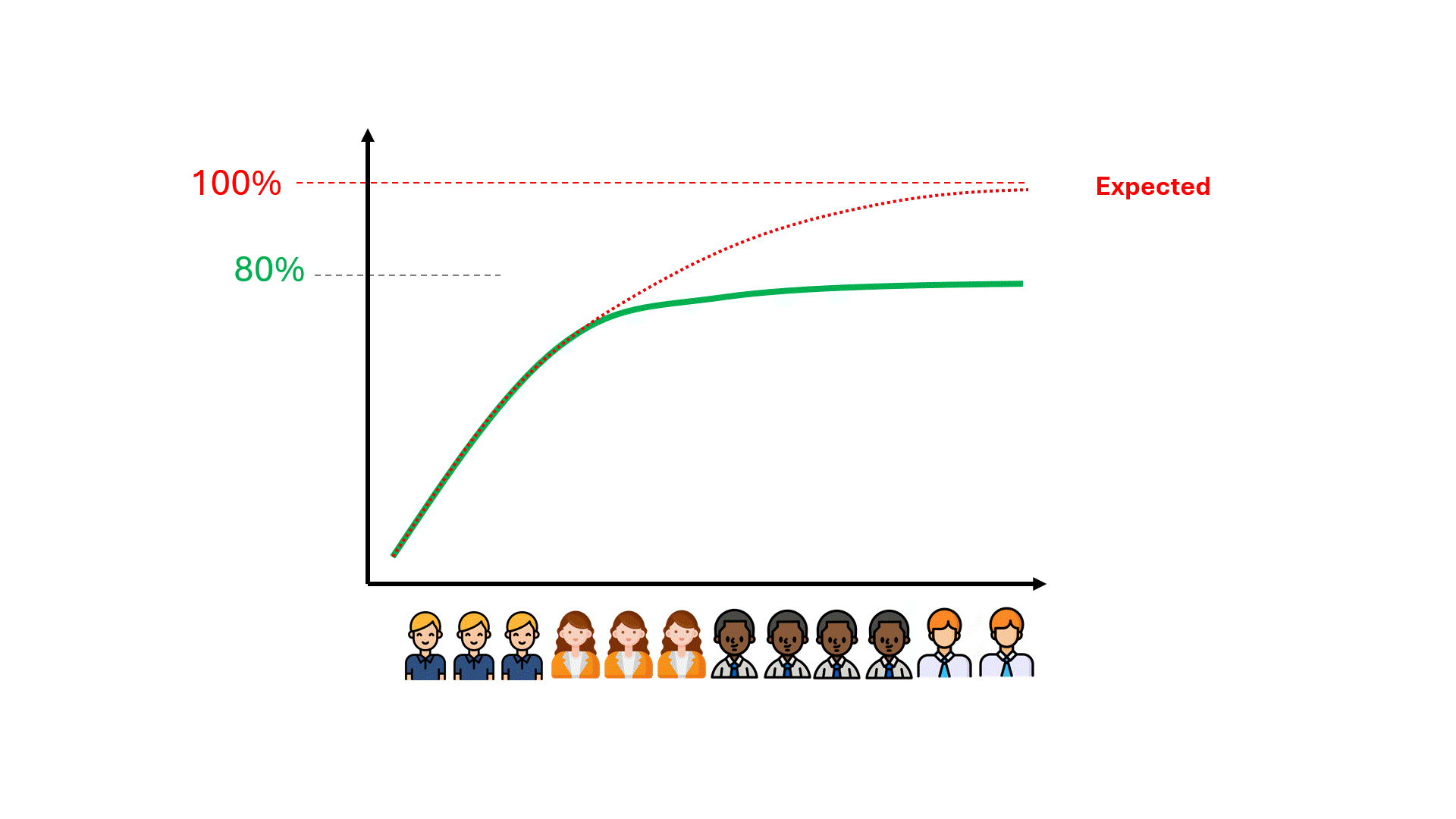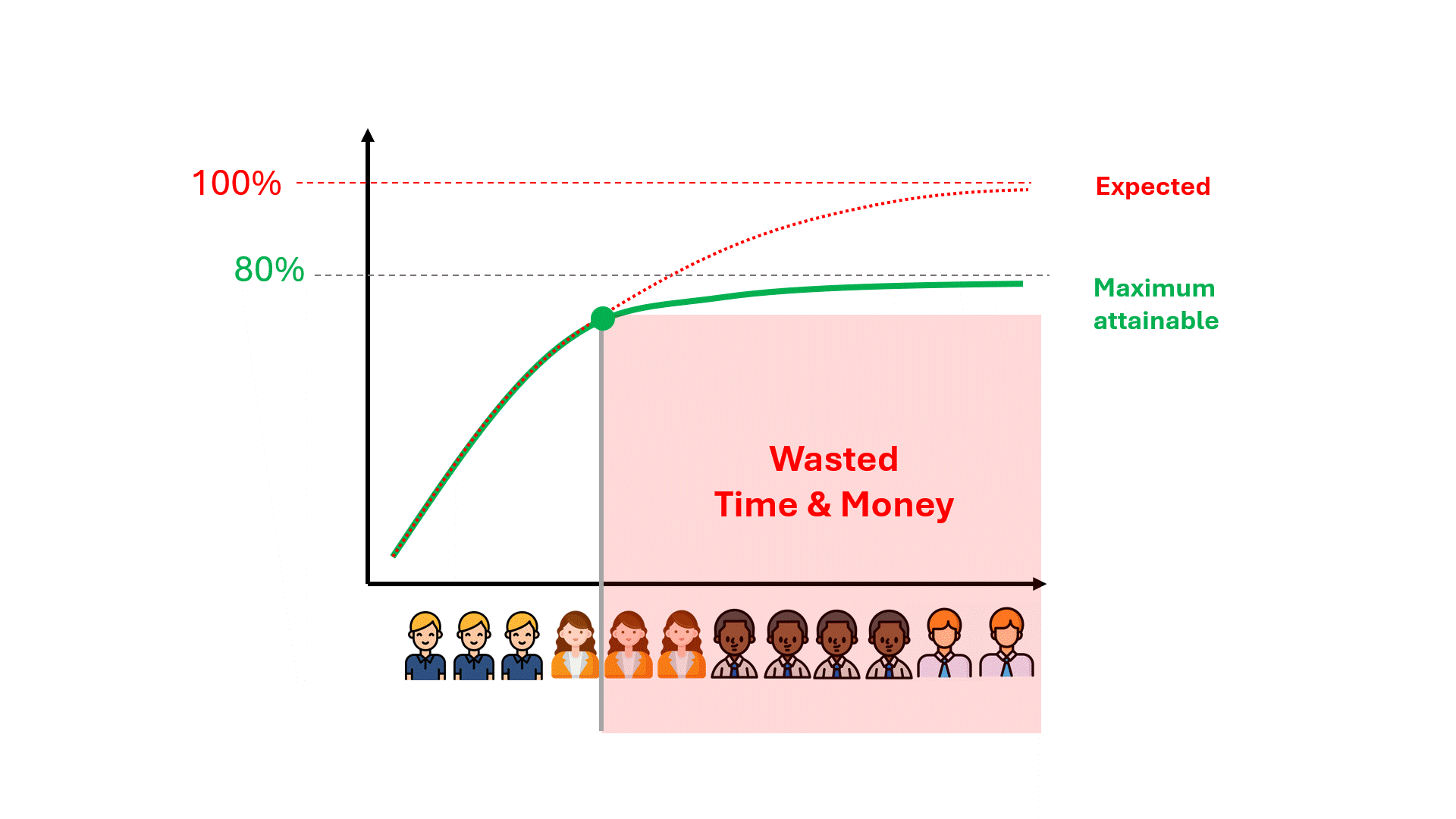
モデルの性能の上限を予測することで、時間や費用、そして期待の失敗を節約できる可能性があるのだろうか?
パフォーマンス・シーリングはすでにデータにエンコードされている
データは、どのようなモデルであっても、将来のパフォーマンスに関する特定の事柄を符号化する。そのひとつが、精度や想起といった指標の性能上限です。 伝統的なTARであろうとGPT8であろうと、使用するモデルに関係なく、すでに持っているデータを使用することで、精度と想起の上限を事前に計算することができます。
データがすでにモデルの性能の基本的な限界を符号化していると言うとき、私たちはどのデータについて話しているのでしょうか-トレーニングデータでしょうか、テストデータ(すなわち、コントロールセット)でしょうか?
現実には両方ありますが、この記事では2つの重要な理由からコントロールセットに焦点を当てます:
-
制御セットはモデルに依存しない。
-
簡単な計算で、性能の天井を計算することができる。
-
言い換えれば、コントロールセットの統計量を分析することで、現在存在しないモデルも含め、どのモデルでも最高のパフォーマンスを導き出すことができる。
成績の天井につながるデータとは?
元のデータに問題がある可能性もあるが(抽出されたテキストが不十分など)、この記事では人間のレビュアーが作成したレビュータグについて話している。結局のところ、パフォーマンスの天井につながるデータの問題は、人間のレビューの性質に帰結する。
どのようなモデルのパフォーマンス上限を予測するにも、各レビュアーについてたった一つの特徴を知るだけで十分なのだ。その特性とは、レビュータグを適用する際にどれだけリベラルか保守的かということである。定量的には、反応率や生成されるデータの豊富さに反映される。

なぜこれがパフォーマンスの上限を決定する重要な要素であるのかを説明するために、2人の典型的なレビュアー(文書を分類する際に気前よくレスポンシブタグをつけるリベラルなレビュアー)と、文書へのタグ付けを特に選択的に行う保守的なレビュアー)を使用します。実際には、レビュアーはどのようにタグ付けを行うかという点で、スペクトル上にあるが、両極端な2つのレビュアーを例示することで、この現象がパフォーマンス上限をもたらす理由を説明するのに役立つだろう。
思考実験その1
問題の根本を理解するために、非常に単純な例を見てみよう。
保守的なレビュアーとリベラルなレビュアーが、それぞれのタグだけでそれぞれのモデルをトレーニングしたとします。
そして、それぞれのモデルを、それぞれのレビュアーのタグだけで構成されたコントロールセットで評価したとします。
以下は、このプロセスの簡単な視覚化です。説明のために、保守的なレビュアーの反応率は10%で、リベラルなレビュアーの反応率は20%です。
問題は、可能な限り最高のパフォーマンス、つまり各審査官に対する各モデルのパフォーマンスの上限はどの程度か、ということだ。
各レビューアのエラーや自己矛盾を取り除けば、各コントロール・セットで可能な最高の性能は、もちろん100%(100%Recallと100%Precision)であろう:

思考実験その2
保守的なレビュアーがトレーニングしたモデルのコントロールセットは、リベラルなレビュアーが作成した。つまり、モデルをトレーニングした人以外のレビューアがコントロールセットを作成したのです。
今、それぞれのコントロールセットで理論的に最高のパフォーマンスとはどのようなものだろうか?
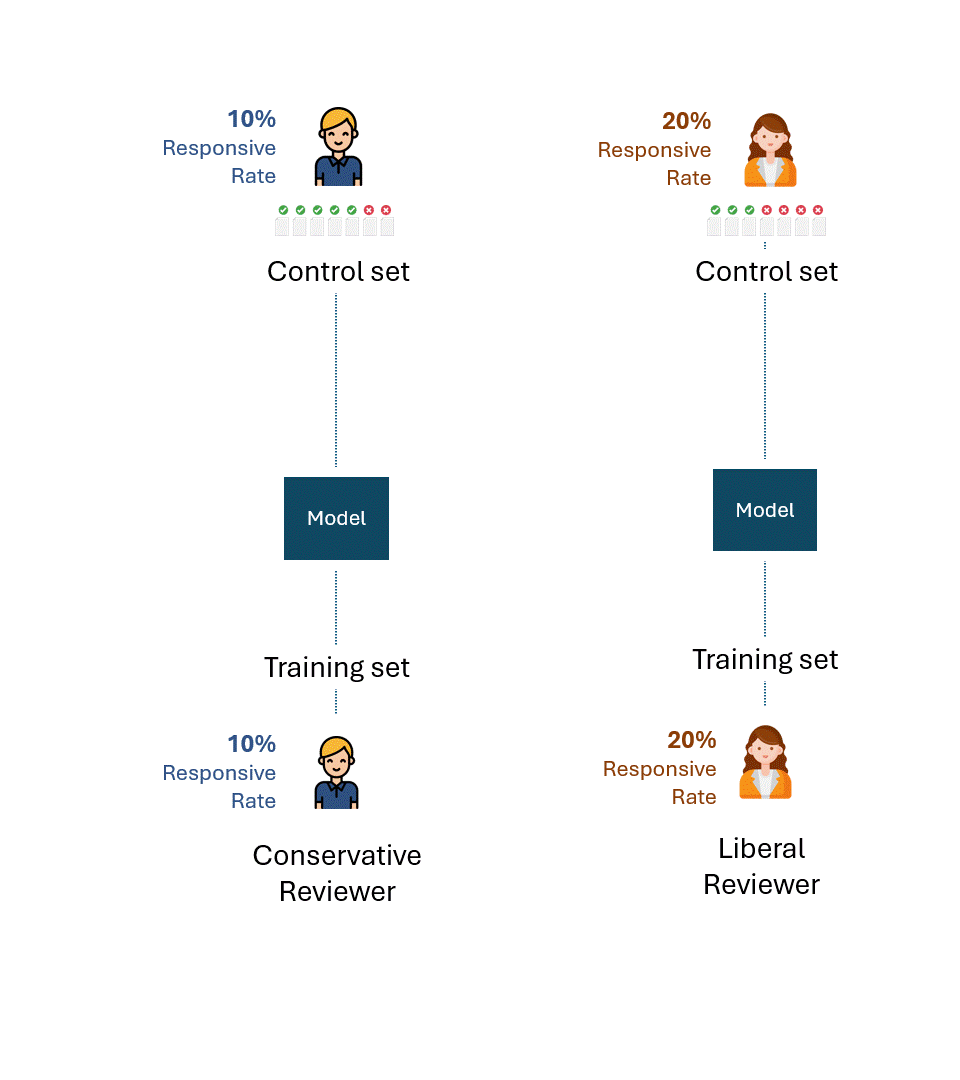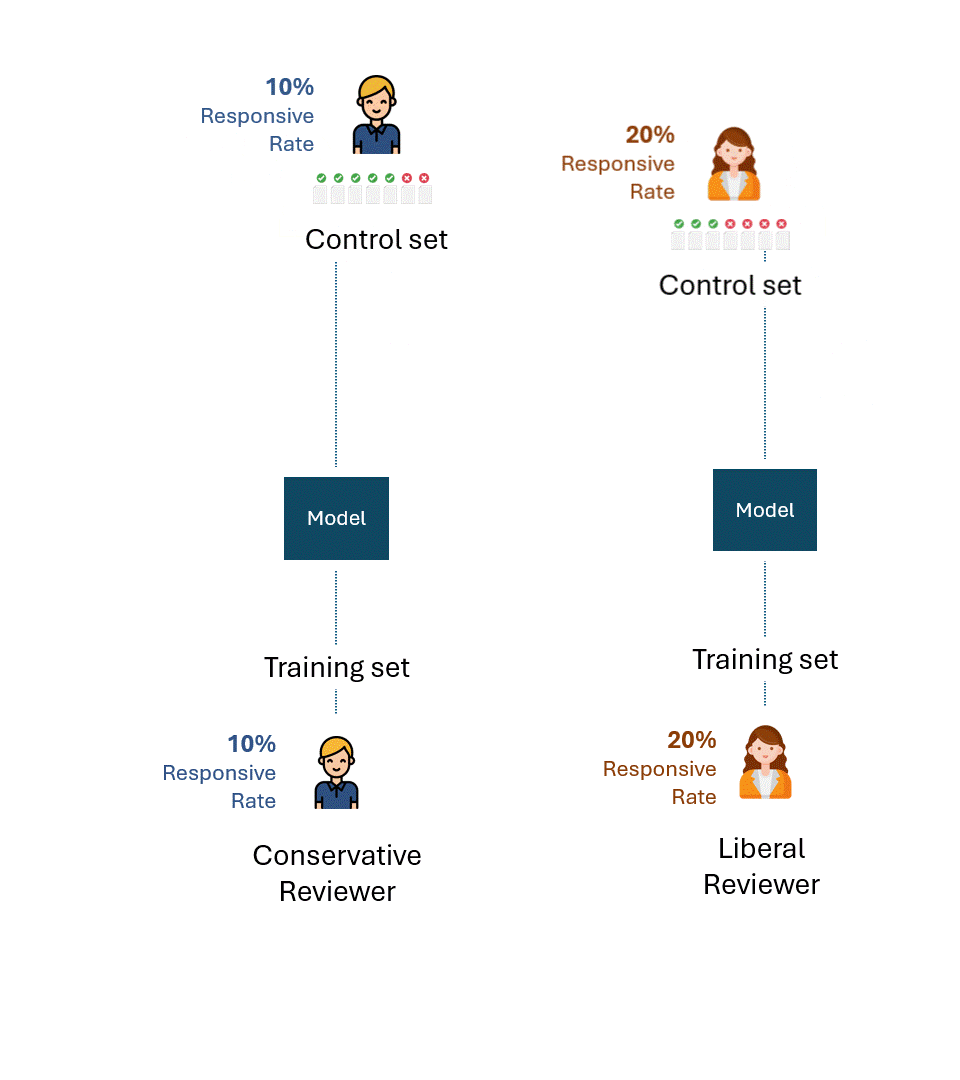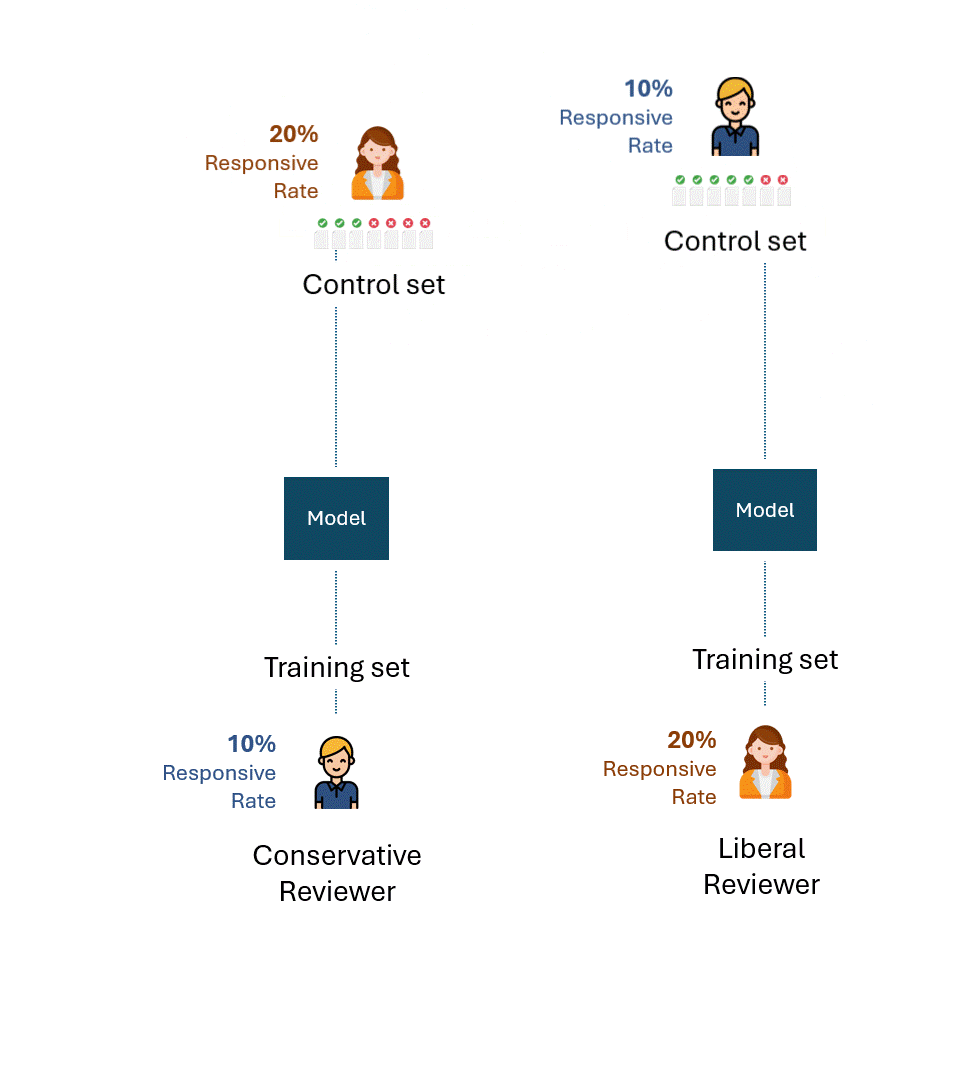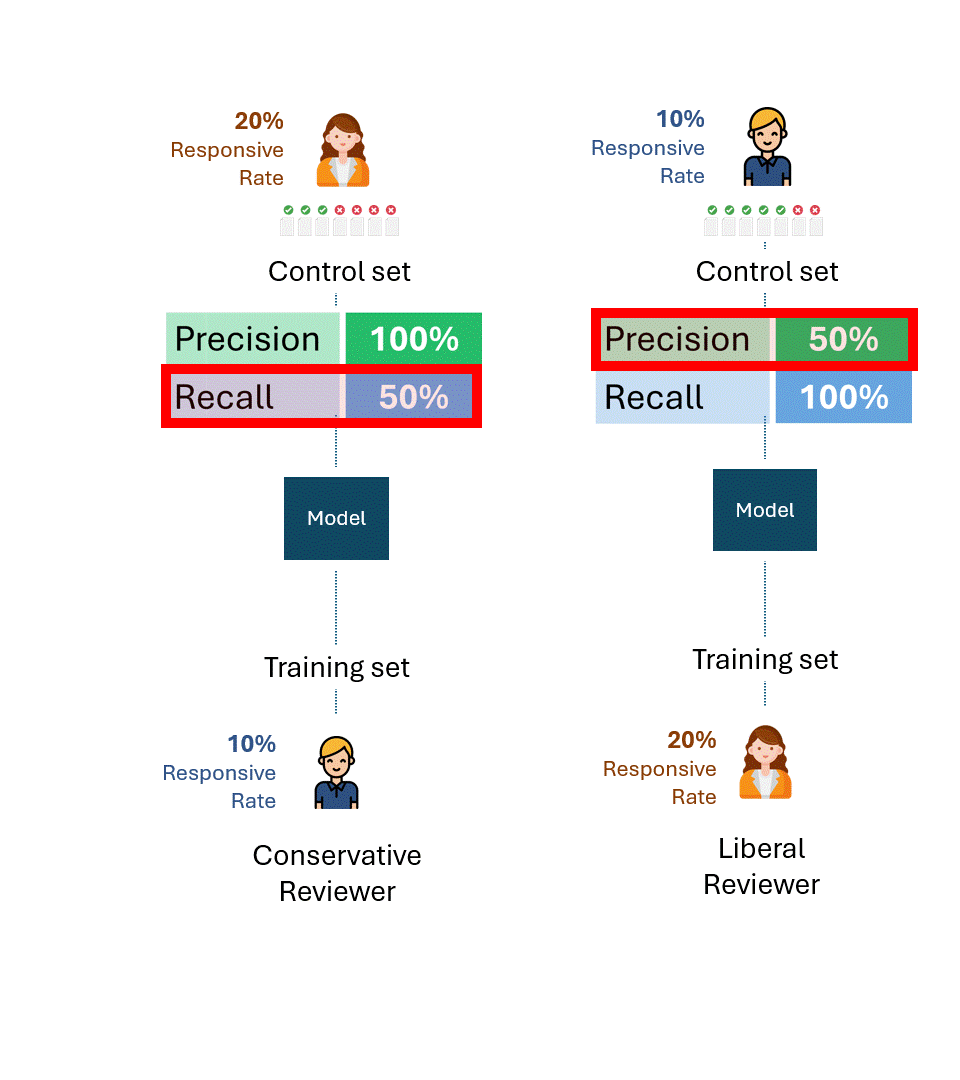
仮に、反応率20%のコントロールセットを作成するリベラルなレビュアーと、反応率10%の保守的なレビュアーが最大限の一貫性を持っていたとしても、彼らは半分にしか反応するタグを付けず、想起率は50%である。
この意味を少し考えてみよう。この想起率を高めるために、保守的なレビュアーがいくらトレーニングしても無駄である。モデルをトレーニングするレビュアーとテストするレビュアー(つまりコントロール・セットを介して)の反応率に根本的な格差があった場合、パフォーマンスは50%を超えて改善することはできない。
これは実際には何を意味するのだろうか?
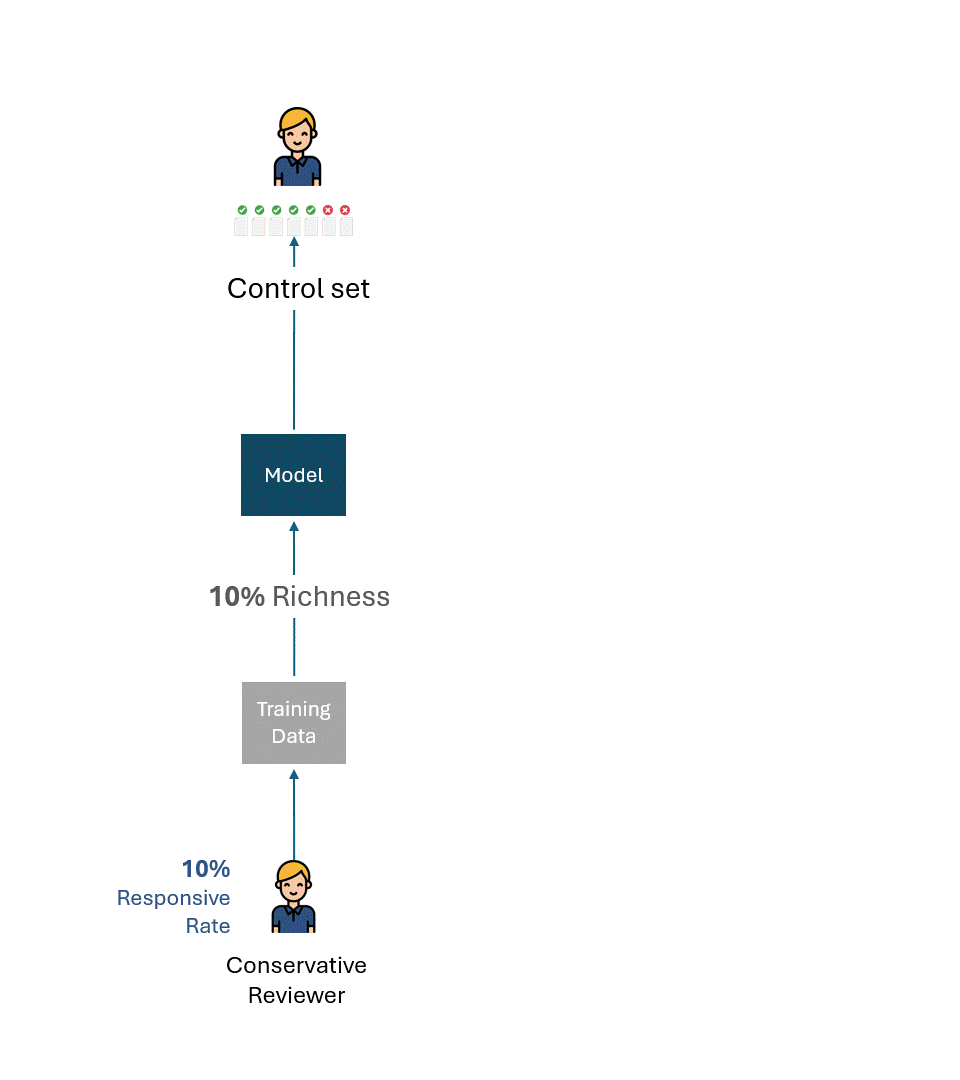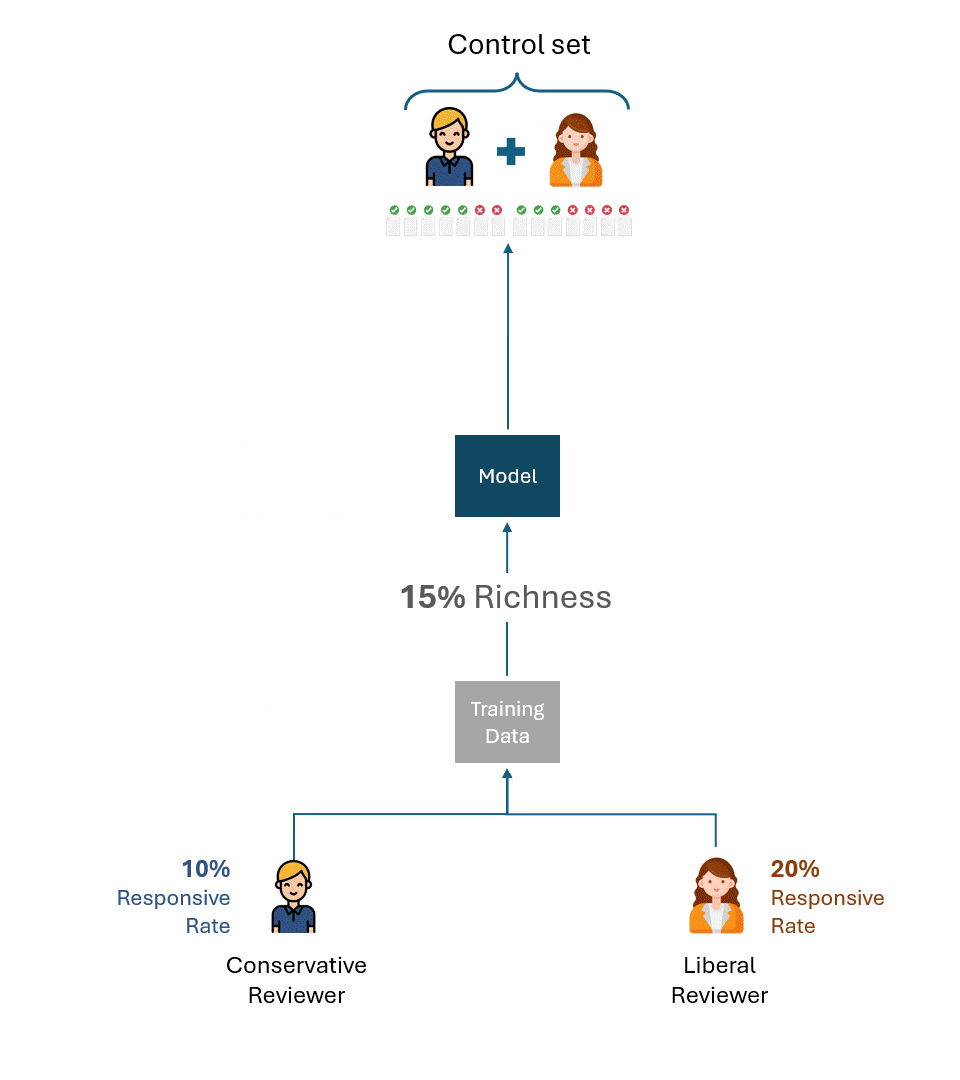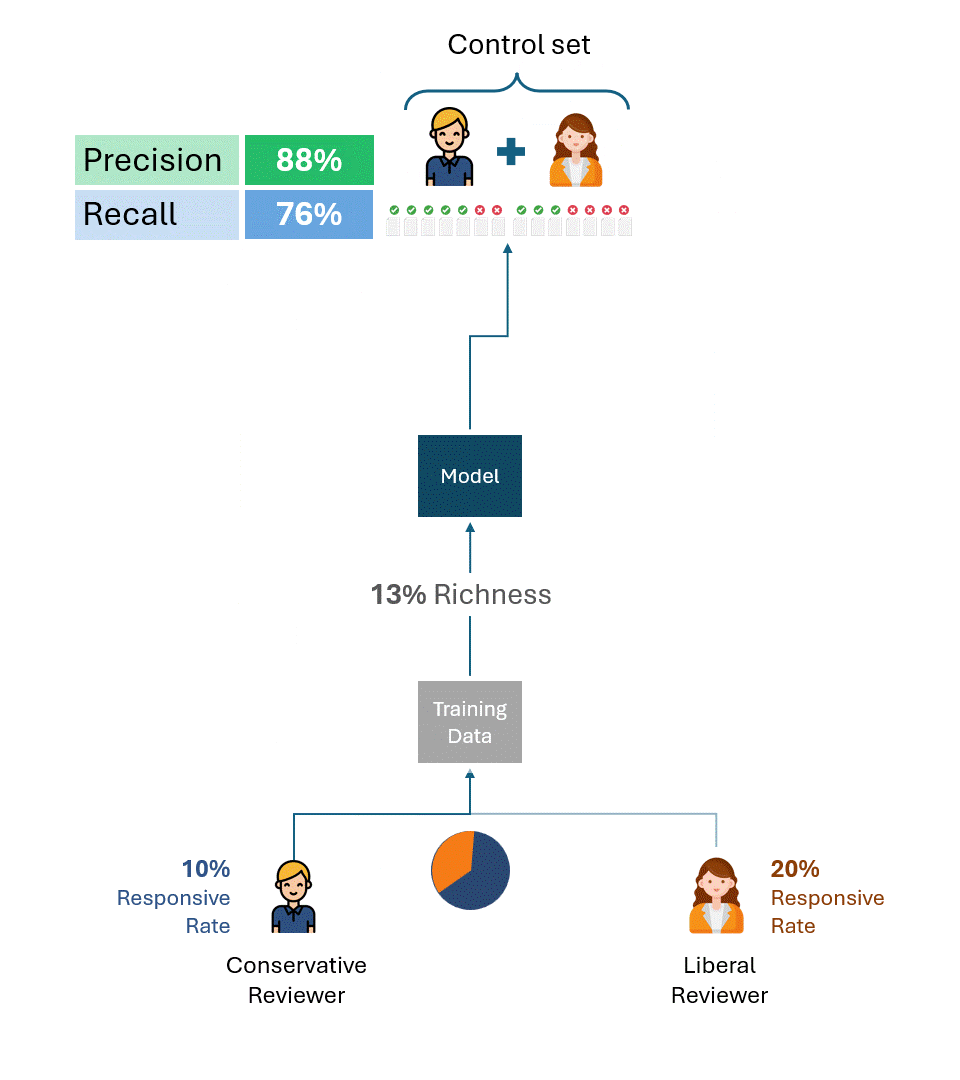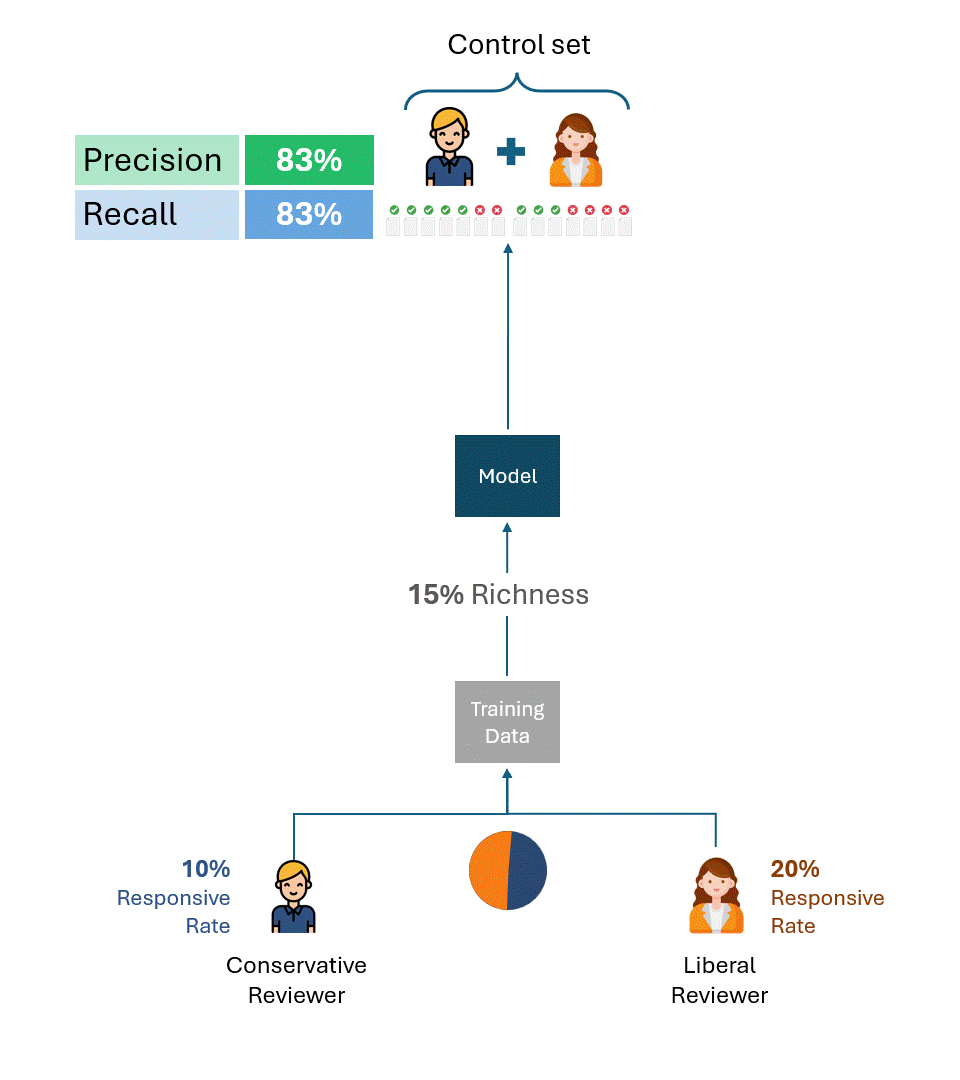
上記の例は、問題の根本的な原因を説明するのに有用である。しかし実際には、複数のレビュアーがトレーニングデータとコントロールセットの両方を作成し、レビュアーはトレーニングデータとコントロールセットの間を含め、様々な割合で存在します。これにより、パフォーマンスの上限を計算する式は複雑になりますが、基本的な結果は変わりません:
対照セットに異なる反応率を持つレビュアーによるタグが含まれている限り、モデルから完全に独立したパフォーマンスの上限が存在する。
これは、訓練データがどのように作成されたかに関係なく、レビュアーの片方(リベラルなレビュアーか保守的なレビュアーか)だけが作成した場合でも、2つのレビュアーの割合的な組み合わせが作成された場合でも同じである。パフォーマンスの上限は、純粋にコントロールセットのみのレビュアーの回答率の格差によって決定されます。
以下は、保守的なレビュアーとリベラルなレビュアーの両方から様々な割合のトレーニングデータを使ってトレーニングしたモデルのパフォーマンス上限を示す例です。ご覧のように、どのシナリオでも100%のパフォーマンスは達成できません。

Igor Labutov、Epiq AI Labsバイスプレジデント
Igor LabutovはEpiqのバイスプレジデントで、Epiq AI Labsの共同リーダーを務めています。Igorはコンピュータ科学者であり、自然言語などの人間の自然な監視から学習する機械学習アルゴリズムの開発に強い関心を持っています。人工知能および機械学習において10年以上の研究経験があります。Labutovはコーネル大学で博士号を取得し、カーネギーメロン大学でポスドク研究員として、人間中心のAIと機械学習の交差点で先駆的な研究を行いました。Epiqに入社する前は、LAER AIを共同設立し、自身の研究を応用して法律業界向けの革新的なテクノロジーを開発しました。