
Angle

LLMの配備方法 その1: モデルはどこにいるのか?
- Legal Transformation
第一世代のAIモデルの初期には、法律業界のテクノロジー・プロバイダーは、「私のモデルはどこに住んでいるのか?」という質問に頻繁に遭遇することはなかった。
モデルはデータが存在する場所に存在するという前提が常にあった。例えば、オンプレミスのeDiscoveryソフトウェアのライセンスを持っている場合、モデルはデータセンターやクラウドインスタンスに「ローカル」に存在していました。
現在、大規模言語モデル(LLM)により、クライアントは膨大な機能と複雑な課題を備えた新しい種類のテクノロジーに直面しています。以下では、ソリューションの品質とパフォーマンス、セキュリティとプライバシーへの影響について、プロバイダーに尋ねるべき質問とその回答を理解する方法について詳しく説明します。
なぜ今なのか?
「このようなモデル、特にLLMは、ソリューション・プロバイダー自身はおろか、ほとんどのフォーチュン100企業が利用できる計算フットプリントを超えてしまったからだ。その結果、LLMを構築し、訓練するリソースを持つ企業はほとんどない。OpenAI GPT、Anthropic Claude、Google Geminiのような企業は、このような大規模な投資を引き受け、API経由でモデルを利用できるようにしている。ここ数年で、APIサービスをソリューションの一部としてパッケージ化するサービス・プロバイダーが何千と生まれた。リーガル・サービスでは、文書レビュー、文書要約、契約書レビューにおいて、このようなイテレーションをよく目にする。
サードパーティのサービスが広く利用できるようになったことは、大きなメリットをもたらすが、同時に、これまで私たちが遭遇したことのない新たな疑問も生じている:
- 私はサードパーティーのLLMとどのような情報を共有しているのか?
- 第三者のLLMとどのような情報を共有するのか?
- もしそうでなければ、誰がそのモデルを管理するのか?
オープンソースのLLMが増え、適切なインフラさえあれば、サードパーティプロバイダーにまったく依存しないデプロイメントを構築できるようになると、質問のリストはさらに長くなる。この場合、サードパーティのサービス・プロバイダーに依存するソリューションを避けることで、何が得られ、何が犠牲になるかを理解することが重要になる。
LLMは通常どのように配置されるのか?
LLMサービスにはいくつかのデプロイメント・オプションがあり、私たちがよく知っているものもあれば、必要に迫られて発展してきたものもある。
契約書レビューや文書レビューのような古典的な第一世代のAIアプリケーションでは、主に分類作業であったため、AIモデルは、自社のデータセンターであろうと、マネージドクラウドであろうと、他のクライアントから切り離されたデータと共に生きるのに十分な大きさであった:
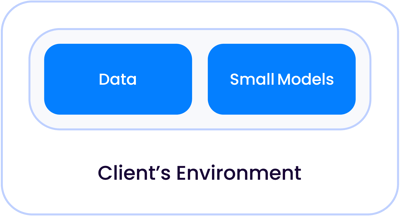
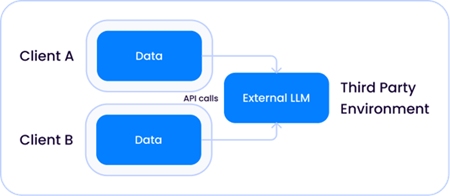
モデルサイズが指数関数的に大きくなり、今日私たちがLLMと呼んでいるものになったとき、これらのモデルがデータに対して相対的に生きることができる2つのケースがある。
1. Open AIのような企業がホストする共有サードパーティ・モデルで、LLMはソリューション・プロバイダーとあなたの環境の両方の外部にある:
2. ソリューション・プロバイダーが直接ホストし、そのクラウド環境で展開するLLM:

(サービスプロバイダは、LLMをホスティングするために多大な計算コストとインフラコストがかかるため、LLMをクライアントが共有するサービスとして展開する可能性が高い)。
今日存在する多様なデプロイメント・アーキテクチャに関するこの入門書を踏まえて、こう問うのは自然なことだ:
ソリューション・プロバイダーがOpenAIのような外部のAPIサービスに依存することにリスクはあるのだろうか?
何事にも言えることだが、一般的な答えは「場合による」である:
1. OpenAIのような第三者が、そのAPIに送信されたデータをどの程度保持するか。
サービスプロバイダはAPIに送信されたデータをどれくらいの期間保持するかについて異なるポリシーを持っており、それらのポリシーはサードパーティのLLM APIプロバイダとの利用規約から流れてくる可能性が高い。
例えば、マイクロソフトはGPT APIに送信された全てのデータに対してデフォルトで30日間の保持ポリシーを設定しています。しかし、ソリューション・プロバイダーはこれらの条件に対する免除を交渉することができ、多くのプロバイダーは0日間の保持ポリシーを取得しています。
しかし、ソリューション・プロバイダーは、これらの条件の免除を交渉することができ、多くのプロバイダーはゼロ日保持ポリシーを取得している。サードパーティのAPIサービス・プロバイダーとどのような保持ポリシーを持っているか、ソリューション・プロバイダーに直接問い合わせ、必要であれば、組織に合わせて最適化することをお勧めする。
データの保持と使用を区別することが重要です。ほとんどのサービス契約では、サードパーティはあなたのデータを使用することはできません。
2. 送信されるデータの性質と量。
データの性質と量は完全にアプリケーション固有である。例えば、公開された裁判所提出書類のような公開データに関してのみ外部APIを使用するソリューションは、クライアントの証拠開示データをAPIに送信するソリューションとは異なるリスクプロファイルをもたらすだろう。さらに掘り下げると、異なるソリューション・プロバイダーは、ディスカバリー・アプリケーション内で、APIに送信するセンシティブ・データの量が大幅に異なる可能性がある。例えば、データの的を絞った質問応答を実行するソリューションは、通常、検索エンジンで検索した文書のスニペットをせいぜい数十個、外部APIに送信する程度だろう。対照的に、サードパーティAPIに依存して文書を分類するソリューションでは、何百万もの文書を送信することになる。
3. サードパーティのサービス利用規約。
最後に、LLM用のサードパーティAPIプロバイダーの数が増えるにつれて、送信されたデータで何ができるかに関して、すべてが同じように作成されているわけではないことを理解することが重要です。例えば、OpenAIが直接提供するGPT-4 APIは、彼らのモデルを改善するためにあなたのデータを明示的に使用できますが、Microsoft Azureを通じて提供される同じGPT-4モデルは使用できません。ソリューション・プロバイダーに、外部APIサービスの利用規約と、具体的にあなたのデータで何ができて、何ができないかを尋ねることが重要です。
独自のLLMモデルを展開するソリューション・プロバイダーについてはどうでしょうか?そこにリスクはあるのか?
ソリューション・プロバイダーがLLM(通常、Llama-3のようなオープン・ソース・モデルの一つをベースにしている)をデプロイする場合、データの保持と使用について直接コントロールすることができる。前述したように、ソリューション・プロバイダーが展開するLLMは、多くの場合、大規模な計算リソースと多額の財政支出を必要とする:
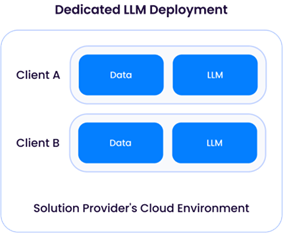
専用LLMデプロイメント」では、ソリューション・プロバイダーが1クライアントだけにコンピュート(CPU/GPU/メモリ)リソースをプロビジョニングする必要がある。この場合、クラウド・プロバイダーから十分なGPUリソースを借りることになり、運用コストが高くなる。このアプローチの利点は、ソリューション・プロバイダーが、他のクライアントのデータと混合することなく、彼らのデータを使ってモデルを改善することで、各クライアントにLLMを柔軟にカスタマイズできることです:
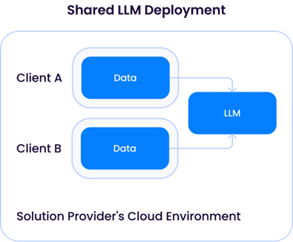
しかし、共有LLMモデルは、先に概説したサードパーティLLMサービス・プロバイダーのインスタンスと同様の問題を引き起こすだろう。一見問題があるように見えるかもしれませんが、異なるクライアントからのデータが基礎となるLLMの更新に使用されない限り、アーキテクチャはOpenAIのようなサードパーティAPIサービスと非常に似ており、(少なくとも理論的には)同じリスクプロファイルを持つことになります。
AIソリューションを提供するEpiqのアプローチと、責任あるAI開発へのコミットメントについては、こちらをご覧ください。
 Igor Labutov、Epiq AI Labsバイスプレジデント
Igor Labutov、Epiq AI Labsバイスプレジデント
Igor LabutovはEpiqの副社長で、Epiq AI Labsの共同リーダーを務めています。Igorはコンピュータ科学者であり、自然言語などの人間の自然な監視から学習する機械学習アルゴリズムの開発に強い関心を持っています。人工知能と機械学習において10年以上の研究経験があります。Labutovはコーネル大学で博士号を取得し、カーネギーメロン大学でポスドク研究員として、人間中心のAIと機械学習の交差点で先駆的な研究を行いました。Epiqに入社する前は、LAER AIを共同設立し、自身の研究を応用して法律業界向けの革新的なテクノロジーを開発しました。