
Angle

Wie man LLMs einsetzt Teil 1: Wo leben Ihre Modelle?
- Legal Transformation
In den Anfängen der ersten Generation von KI-Modellen wurde den Technologieanbietern der Rechtsbranche nicht häufig die Frage gestellt: „Wo leben meine Modelle?“
Es wurde immer davon ausgegangen, dass die Modelle dort leben, wo die Daten leben. Wenn Sie beispielsweise eine lokale eDiscovery-Softwarelizenz besaßen, befanden sich die Modelle „lokal“ in Ihrem Rechenzentrum oder in einer Cloud-Instanz.
Mit den Large Language Models (LLMs) stehen die Kunden nun vor einer neuen Art von Technologie mit enormen Möglichkeiten und komplexen Herausforderungen. Im Folgenden erläutern wir, welche Fragen Sie Ihrem Anbieter stellen sollten und wie Sie seine Antworten in Bezug auf die Qualität und Leistung seiner Lösung sowie die Auswirkungen auf Sicherheit und Datenschutz verstehen können.
Warum jetzt fragen?
Die Frage „Wo ist Ihr Modell untergebracht?“ wird plötzlich häufig gestellt, weil diese Modelle, insbesondere LLMs, die Rechenkapazitäten der meisten Fortune-100-Unternehmen übersteigen, ganz zu schweigen von den Lösungsanbietern selbst. Infolgedessen haben nur sehr wenige Unternehmen die Ressourcen, um LLMs zu entwickeln und zu trainieren. Unternehmen wie OpenAI GPT, Anthropic Claude und Google Gemini haben diese massiven Investitionen auf sich genommen und ihre Modelle über APIs verfügbar gemacht. In den letzten Jahren haben sie Tausende von Dienstleistern hervorgebracht, die diesen API-Service als Teil ihrer Lösungen anbieten. Bei juristischen Dienstleistungen sehen wir diese Iterationen häufig bei der Überprüfung von Dokumenten, der Zusammenfassung von Dokumenten und der Überprüfung von Verträgen.
Die breite Verfügbarkeit von Diensten Dritter bringt erhebliche Vorteile mit sich, wirft aber auch neue Fragen auf, denen wir bisher nicht begegnet sind:
- Welche Informationen gebe ich an LLMs von Dritten weiter?
- Werden meine Informationen gespeichert und zur Verbesserung ihrer Modelle verwendet?
- Habe ich die Kontrolle über diese Modelle, und wenn nicht, wer hat sie?
Die Liste der Fragen wird immer länger, je mehr Open-Source-LLMs zur Verfügung stehen, die es mit der richtigen Infrastruktur ermöglichen, Implementierungen zu erstellen, die überhaupt nicht auf Drittanbieter angewiesen sind. In diesem Fall ist es wichtig zu verstehen, was Sie gewinnen und was Sie opfern würden, wenn Sie Lösungen vermeiden, die auf Drittanbieter angewiesen sind.
Wie werden LLMs typischerweise eingesetzt?
Es gibt mehrere Bereitstellungsoptionen für einen LLM-Dienst, von denen einige uns vielleicht bekannt sind und andere sich aus der Notwendigkeit heraus entwickelt haben.
Bei einer klassischen KI-Anwendung der ersten Generation, wie z. B. der Überprüfung von Verträgen oder Dokumenten, bei denen es sich in erster Linie um Klassifizierungsaufgaben handelte, waren die KI-Modelle klein genug, um zusammen mit Ihren Daten zu leben, sei es in Ihrem eigenen Rechenzentrum oder in einer verwalteten Cloud, getrennt von anderen Kunden:
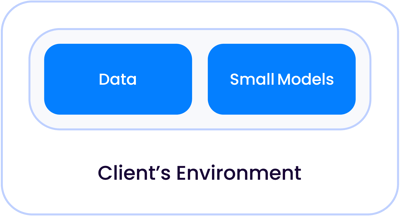
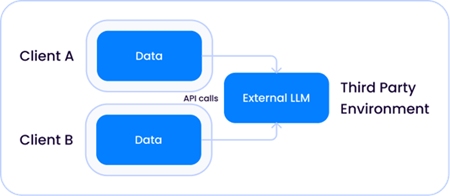
Da die Modellgrößen exponentiell wuchsen und zu dem wurden, was wir heute LLMs nennen, gibt es zwei Fälle, in denen diese Modelle relativ zu Ihren Daten leben können.
1. Ein gemeinsam genutztes Modell eines Drittanbieters, das von einem Unternehmen wie Open AI gehostet wird, wobei das LLM sowohl für den Lösungsanbieter als auch für Ihre Umgebung extern ist:
2. Ein LLM, das direkt von Ihrem Lösungsanbieter in dessen Cloud-Umgebung gehostet und bereitgestellt wird:

(Dienstanbieter haben erhebliche Rechen- und Infrastrukturkosten für das Hosten von LLMs und werden daher wahrscheinlich LLMs als einen von ihren Kunden gemeinsam genutzten Dienst einsetzen).
In Anbetracht dieser Einführung in die Vielfalt der heute existierenden Einsatzarchitekturen stellt sich natürlich die Frage:
Besteht ein Risiko, wenn sich ein Lösungsanbieter auf einen externen API-Dienst wie OpenAI verlässt?
Wie bei allem lautet die allgemeine Antwort: „Es kommt darauf an“ - beachten Sie drei Faktoren:
1. Das Ausmaß, in dem ein Dritter, wie OpenAI, die an seine API gesendeten Daten speichert.
Dienstanbieter haben unterschiedliche Richtlinien darüber, wie lange sie die an ihre APIs gesendeten Daten aufbewahren, und diese Richtlinien werden sich wahrscheinlich aus den Dienstbedingungen mit ihren LLM-API-Drittanbietern ergeben.
Microsoft hat beispielsweise eine Standardaufbewahrungsrichtlinie von 30 Tagen für alle Daten, die an seine GPT-API gesendet werden; Lösungsanbieter können jedoch Ausnahmen von diesen Bedingungen aushandeln, und viele haben eine Null-Tage-Aufbewahrungsrichtlinie erreicht.
Wir empfehlen, dass Sie sich direkt bei Ihrem Lösungsanbieter nach der Aufbewahrungsrichtlinie erkundigen, die er mit dem Drittanbieter-API-Dienstanbieter vereinbart hat, und diese bei Bedarf für Ihr Unternehmen optimieren.
Es ist wichtig, zwischen der Aufbewahrung und der Nutzung Ihrer Daten zu unterscheiden. Vorratsdatenspeicherung bedeutet nicht, dass der Drittanbieter Ihre Daten zum Trainieren seiner Modelle verwenden kann - nach den meisten Dienstleistungsvereinbarungen darf der Drittanbieter Ihre Daten nicht verwenden.
2. Die Art und Menge der übermittelten Daten.
Die Art und Menge der Daten ist völlig anwendungsspezifisch. So würde beispielsweise eine Lösung, die eine externe API nur für öffentliche Daten wie öffentliche Gerichtsakten verwendet, ein anderes Risikoprofil aufweisen als eine Lösung, die die Ermittlungsdaten eines Kunden an die API sendet. Bei genauerer Betrachtung können verschiedene Lösungsanbieter im Rahmen von Discovery-Anwendungen drastisch unterschiedliche Mengen an sensiblen Daten an die API senden. So würden beispielsweise Lösungen, die eine gezielte Fragebeantwortung von Daten durchführen, in der Regel höchstens ein Dutzend Ausschnitte von Dokumenten, die über eine Suchmaschine abgerufen wurden, an eine externe API senden. Im Gegensatz dazu würden Lösungen, die die Drittanbieter-API zur Klassifizierung von Dokumenten nutzen, Millionen von Dokumenten senden.
3. Nutzungsbedingungen von Drittanbietern darüber, was diese mit Ihren Daten tun können.
Schließlich ist es wichtig zu verstehen, dass mit der wachsenden Zahl von Drittanbietern von APIs für LLMs nicht alle gleich sind in Bezug darauf, was sie mit den an sie gesendeten Daten tun können. Beispielsweise kann die direkt von OpenAI bereitgestellte GPT-4-API Ihre Daten ausdrücklich zur Verbesserung ihrer Modelle verwenden, während das gleiche GPT-4-Modell, das über Microsoft Azure bereitgestellt wird, dies nicht kann. Es ist wichtig, dass Sie sich bei Ihrem Lösungsanbieter nach den Nutzungsbedingungen seines externen API-Dienstes erkundigen und erfahren, was genau er mit Ihren Daten tun kann und was nicht.
Was ist mit Lösungsanbietern, die ihre eigenen LLM-Modelle einsetzen? Gibt es hier Risiken?
Wenn der Lösungsanbieter ein LLM einsetzt (in der Regel auf der Grundlage eines der verfügbaren Open-Source-Modelle, wie z. B. Llama-3), hat er die direkte Kontrolle über die Datenspeicherung und -nutzung. Wie bereits erwähnt, erfordert ein LLM, das von einem Lösungsanbieter eingesetzt wird, oft umfangreiche Rechenressourcen - und erhebliche finanzielle Ausgaben - und daher sehr wahrscheinlich eine gemeinsame Architektur:
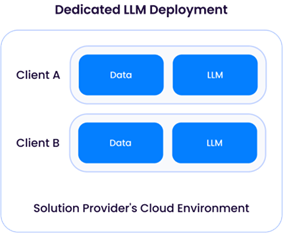
Eine „dedizierte LLM-Bereitstellung“ erfordert, dass ein Lösungsanbieter Rechenressourcen (CPU/GPU/Speicher) für nur einen Kunden bereitstellt. Dies würde bedeuten, dass ausreichend GPU-Ressourcen von einem Cloud-Anbieter gemietet werden müssten, was zu höheren Betriebskosten führt. Der Vorteil dieses Ansatzes ist die Flexibilität des Lösungsanbieters, den LLM an jeden Kunden anzupassen, indem er dessen Daten zur Verbesserung des Modells verwendet, ohne sie mit Daten anderer Kunden zu vermischen:
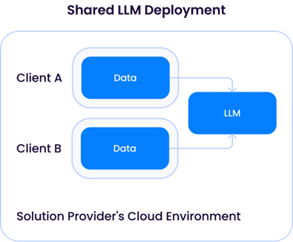
Das Modell der gemeinsam genutzten LLM würde jedoch ähnliche Probleme aufwerfen wie die zuvor beschriebene Instanz des LLM-Dienstanbieters eines Drittanbieters. Auch wenn es auf den ersten Blick besorgniserregend erscheinen mag, solange Daten von verschiedenen Kunden nicht verwendet werden, um die zugrunde liegende LLM zu aktualisieren, wäre die Architektur der eines Drittanbieter-API-Dienstes wie OpenAI sehr ähnlich und hätte (zumindest theoretisch) das gleiche Risikoprofil.
Erfahren Sie mehr über Epiqs Ansatz zur Bereitstellung von KI-Lösungen und sein Engagement für eine verantwortungsvolle KI-Entwicklung.
 Igor Labutov, Vizepräsident, Epiq AI Labs
Igor Labutov, Vizepräsident, Epiq AI Labs
Igor Labutov ist Vizepräsident bei Epiq und Co-Leiter der Epiq AI Labs. Igor ist Informatiker mit einem starken Interesse an der Entwicklung von Algorithmen für das maschinelle Lernen, die aus der natürlichen Überwachung durch den Menschen lernen, z. B. aus der natürlichen Sprache. Er verfügt über mehr als 10 Jahre Forschungserfahrung in den Bereichen Künstliche Intelligenz und maschinelles Lernen. Labutov promovierte an der Cornell University und war als Post-Doc an der Carnegie Mellon University tätig, wo er bahnbrechende Forschungen an der Schnittstelle zwischen menschenzentrierter KI und maschinellem Lernen durchführte. Bevor er zu Epiq kam, war Labutov Mitbegründer von LAER AI, wo er seine Forschungsergebnisse zur Entwicklung neuer Technologien für die Rechtsbranche einsetzte.
Der Inhalt dieses Artikels dient lediglich der allgemeinen Information und stellt keine Rechtsberatung dar.
Subscribe to Future Blog Posts
