
Angle

Ihr Modell versagt nicht - Ihre Daten schon
- 3 Minuten
Modellleistung: Erwartung vs. Realität
Was ist Ihr erster Instinkt, wenn Ihr TAR-Modell bei einem Kontrollsatz schlecht abschneidet?
Die gängige Meinung ist, dass mehr Trainingsdaten (sprich: mehr Überprüfungsaufwand) dazu beitragen würden, die Leistung in Bezug auf Recall und Precision dorthin zu bringen, wo Sie sie haben möchten - und mit genügend Geld und Zeit nahe an 100 %.
Leider kann es Hunderte von vergeudeten Überprüfungsstunden dauern, bis man merkt, dass die Leistung des Modells bei einer Zahl endet, die alles andere als ideal ist.
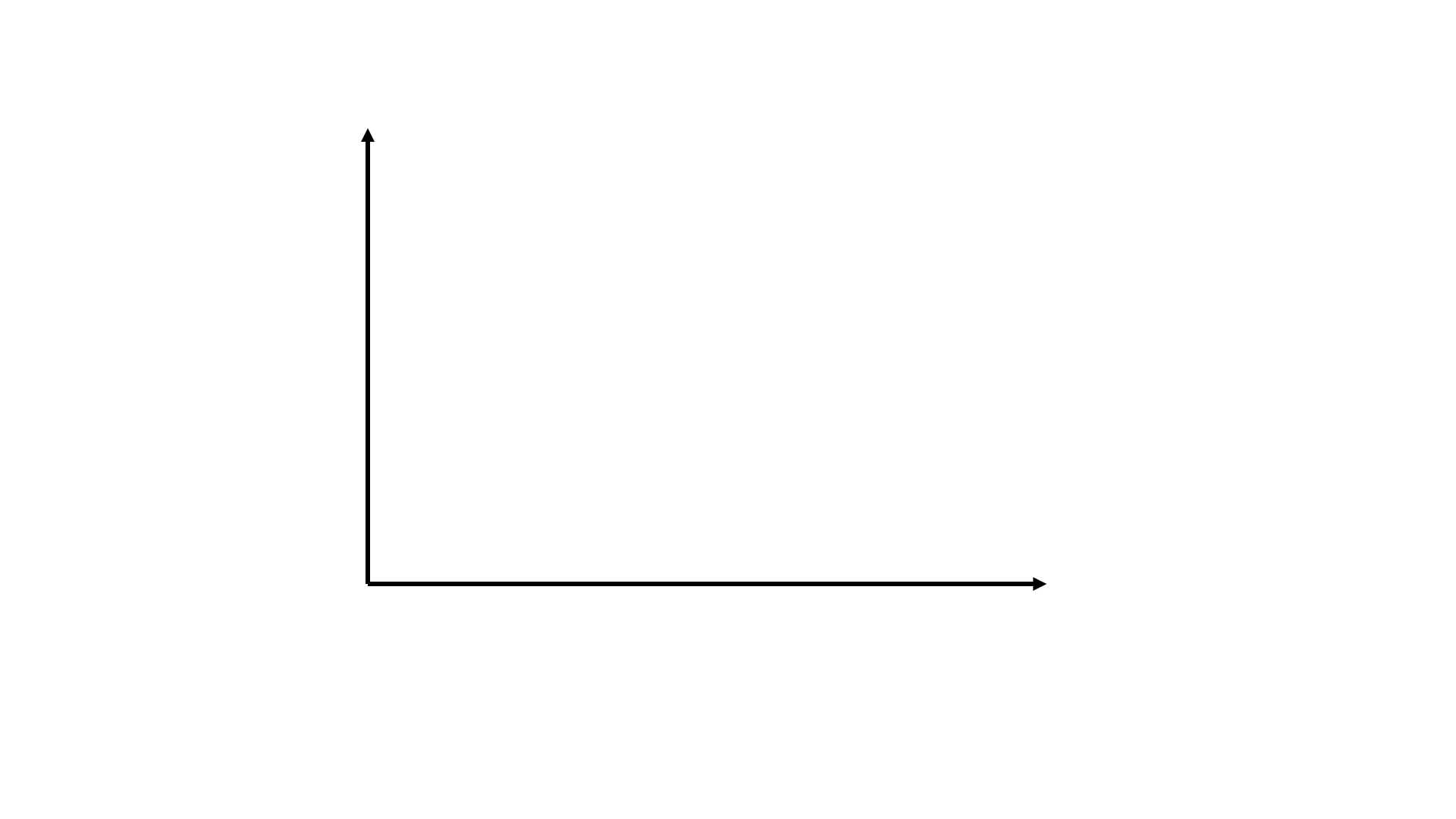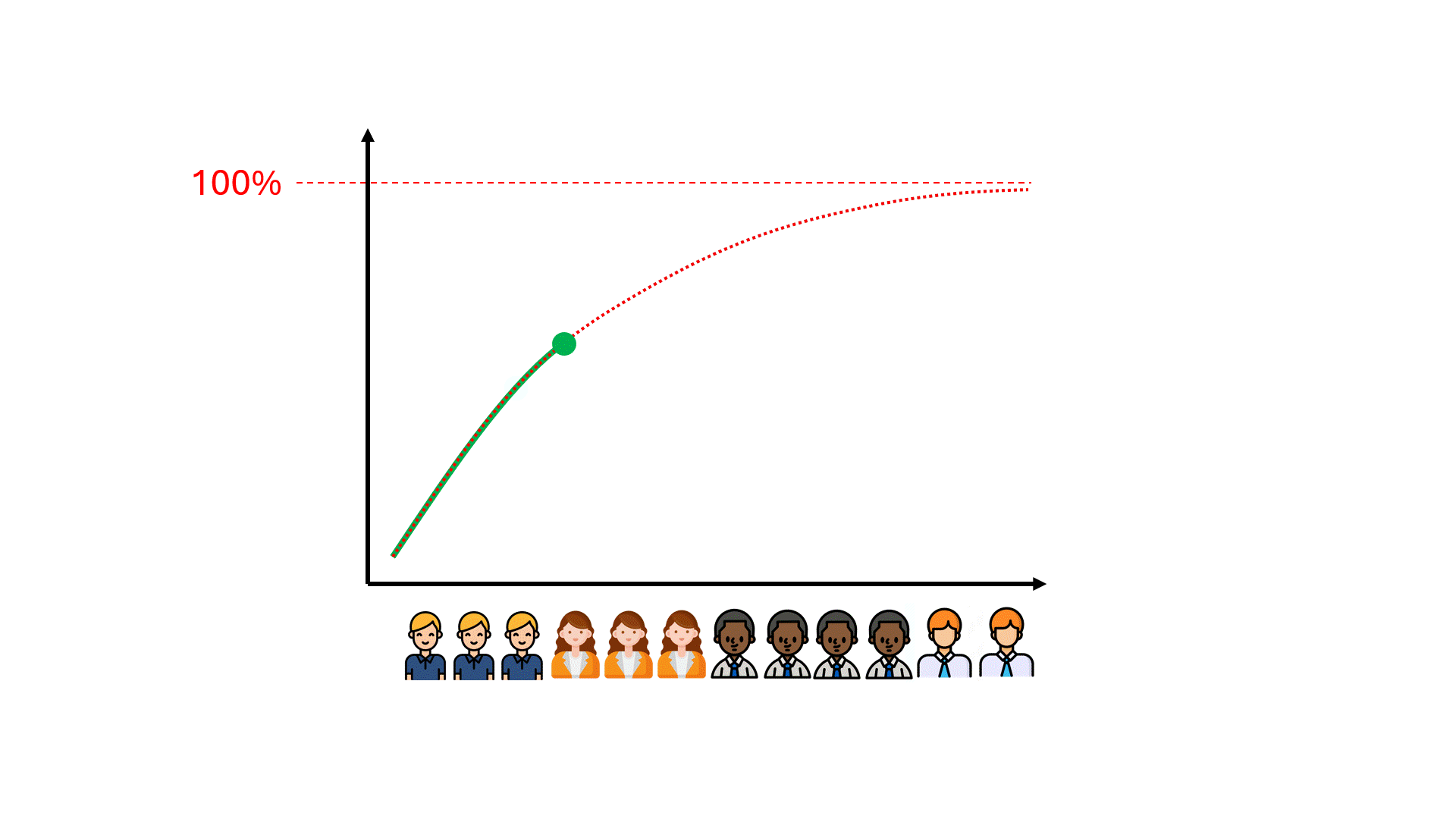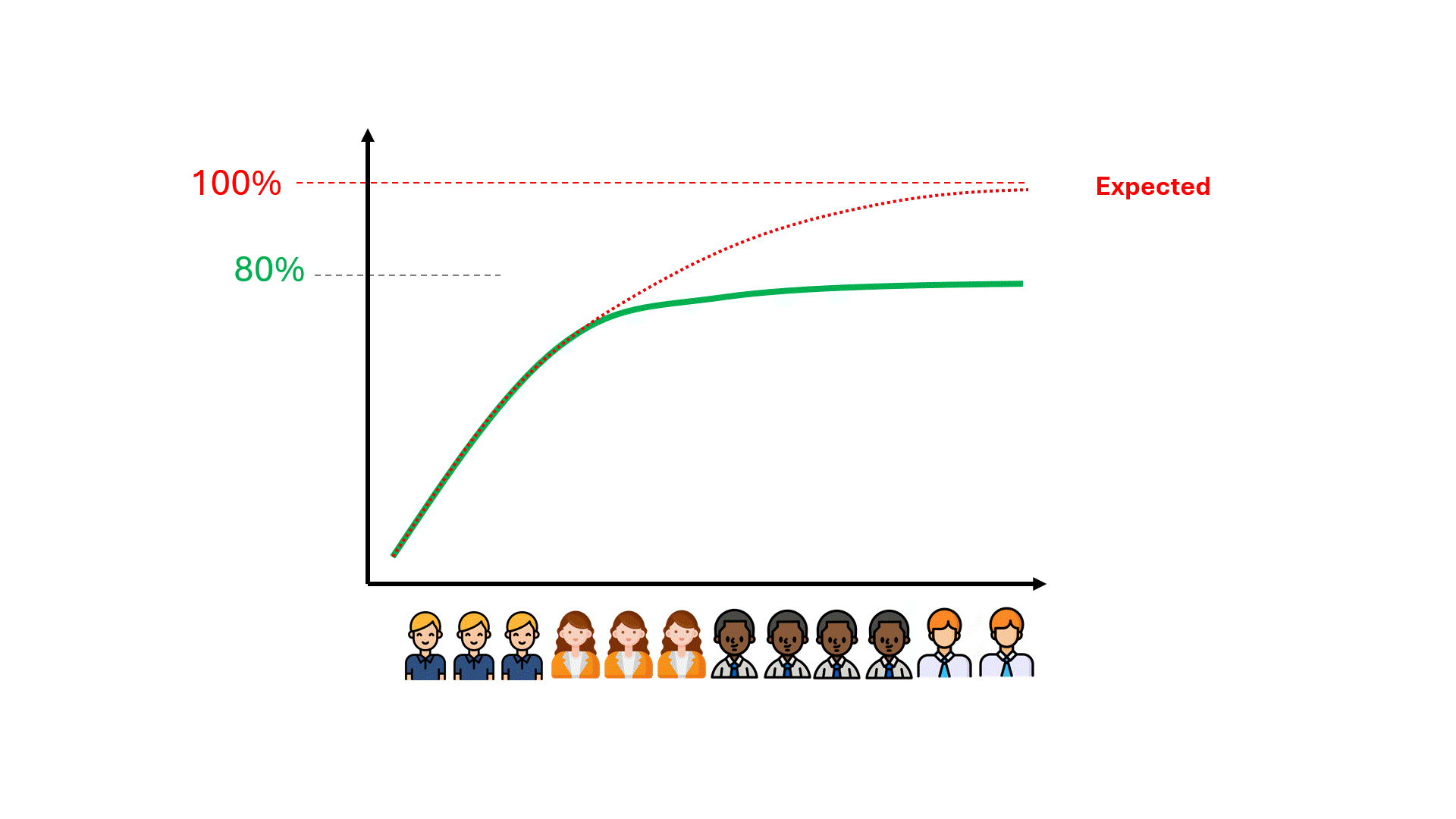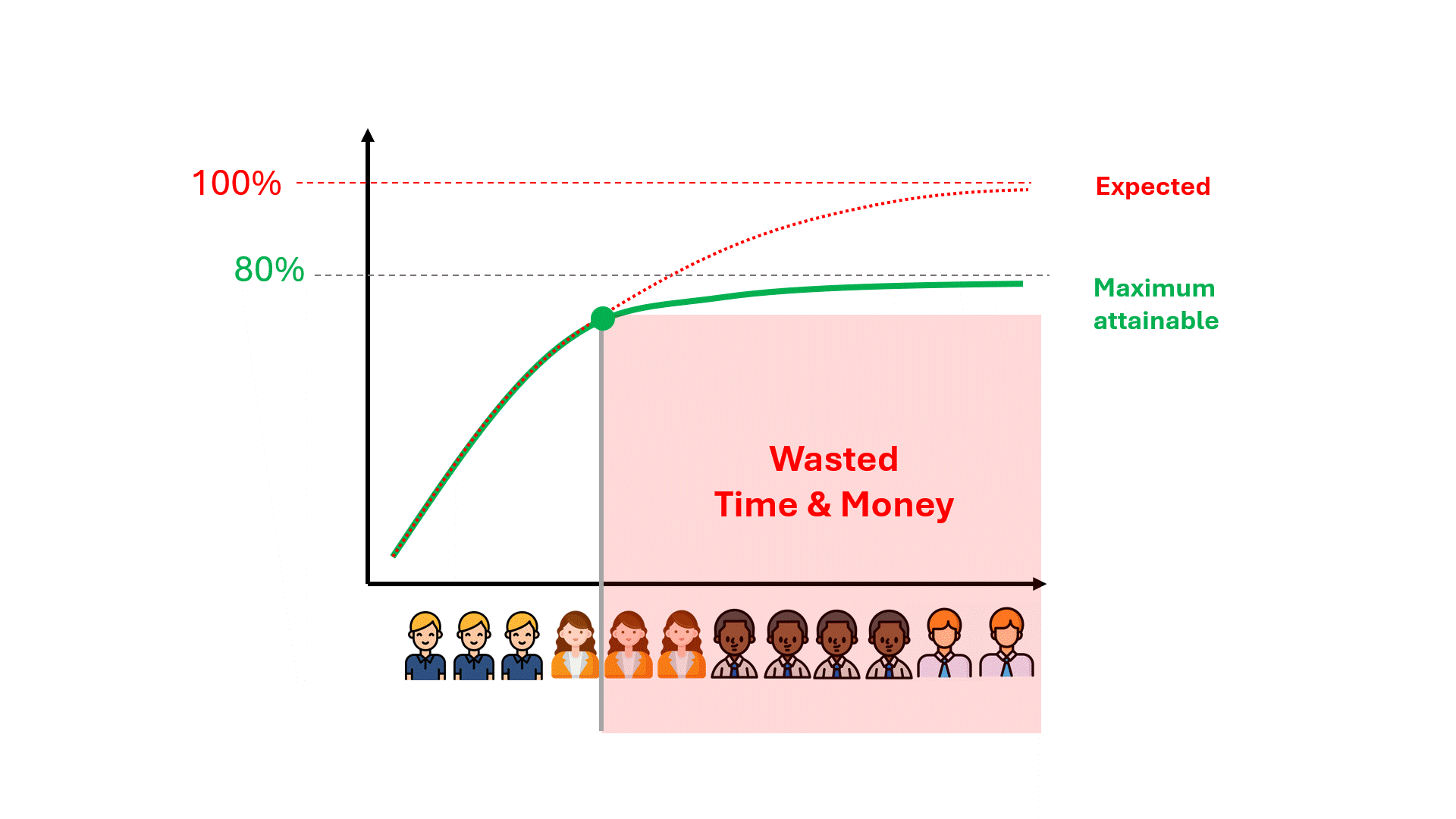
Können wir die Obergrenze für die Leistung des Modells vorhersehen und so möglicherweise Zeit, Geld und enttäuschte Erwartungen einsparen?
Die Leistungsobergrenze ist bereits in Ihren Daten kodiert
Daten kodieren bestimmte Dinge über die zukünftige Leistung eines Modells. Eines dieser Dinge ist die Leistungsgrenze für Metriken wie Precision und Recall. Unabhängig davon, ob es sich um herkömmliche TAR oder GPT8 handelt, können Sie die Präzisions- und Recall-Grenzen unabhängig von dem von Ihnen verwendeten Modell im Voraus berechnen, indem Sie die bereits vorhandenen Daten verwenden.
Wenn wir sagen, dass die Daten bereits die grundlegende Grenze für die Leistung Ihres Modells kodieren, welche Daten meinen wir dann - Trainings- oder Testdaten (d. h. Kontrollsatz)?
In Wirklichkeit geht es um beides, aber in diesem Artikel konzentrieren wir uns aus zwei wichtigen Gründen auf die Kontrolldaten:
-
Der Kontrollsatz ist völlig modellunabhängig.
-
Es ist möglich - durch einfache Mathematik - die Leistungsobergrenzen zu berechnen.
-
Mit anderen Worten: Durch die Analyse der Statistiken Ihres Kontrollsatzes können wir die beste Leistung für jedes Modell ableiten, auch für solche, die es heute noch nicht gibt.
Was an den Daten führt zu Leistungsbeschränkungen?
Auch wenn es Probleme mit den Originaldaten geben kann (z. B. schlecht extrahierter Text), geht es in diesem Artikel um die von menschlichen Prüfern erstellten Prüfkennzeichen. Es stellt sich heraus, dass Probleme mit Daten, die zu Leistungsobergrenzen führen, auf die Art der menschlichen Überprüfung zurückzuführen sind.
Es reicht völlig aus, ein einziges Merkmal über jeden Rezensenten zu kennen, um die Leistungsobergrenze eines beliebigen Modells vorherzusagen. Diese Eigenschaft besteht darin, wie liberal oder konservativ sie bei der Anwendung von Bewertungskennzeichen sind. Quantitativ spiegelt sich dies in ihrer Reaktionsrate oder der Fülle der von ihnen generierten Daten wider.

Um zu veranschaulichen, warum dies ein entscheidender Faktor für die Leistungsobergrenze ist, werden wir zwei prototypische Gutachter heranziehen - einen liberalen Gutachter, der bei der Klassifizierung von Dokumenten großzügig das responsive Tag vergibt, und einen konservativen Gutachter, der bei der Kennzeichnung von Dokumenten besonders selektiv vorgeht. In der Realität bewegen sich die Prüfer in Bezug auf die Art der Kennzeichnung auf einem Spektrum, aber die Darstellung der beiden Extreme wird helfen zu erklären, warum dieses Phänomen zu einer Leistungsobergrenze führt.
Gedankenexperiment Nr. 1
Um die Wurzel des Problems zu verstehen, lassen Sie uns ein sehr einfaches Beispiel betrachten.
Stellen Sie sich vor, die konservativen und die liberalen Gutachter trainierten ihre jeweiligen Modelle nur anhand ihrer Tags.
Dann nehmen wir an, dass jedes Modell anhand von Kontrollsätzen bewertet wurde, die nur aus den Tags des jeweiligen Bewerters bestanden.
Unten sehen Sie eine einfache Visualisierung dieses Prozesses. Zur Veranschaulichung: Der konservative Gutachter hat eine Ansprechrate von 10 % und der liberale Gutachter eine Ansprechrate von 20 %.
Die Frage ist: Was ist die bestmögliche Leistung, d. h. die Leistungsobergrenze jedes Modells für jeden Prüfer?
Wenn wir die Fehler oder die Selbstinkonsistenz jedes Gutachters abziehen, wäre die bestmögliche Leistung für jeden Kontrollsatz natürlich 100 % (100 % Recall und 100 % Precision):

Gedankenexperiment #2
Stellen wir uns nun eine leicht veränderte Situation vor: Die Kontrollmenge für das vom konservativen Gutachter trainierte Modell wurde vom liberalen Gutachter erstellt und umgekehrt. Mit anderen Worten: Ein anderer Gutachter als derjenige, der das Modell trainiert hat, hat den Kontrollsatz erstellt.
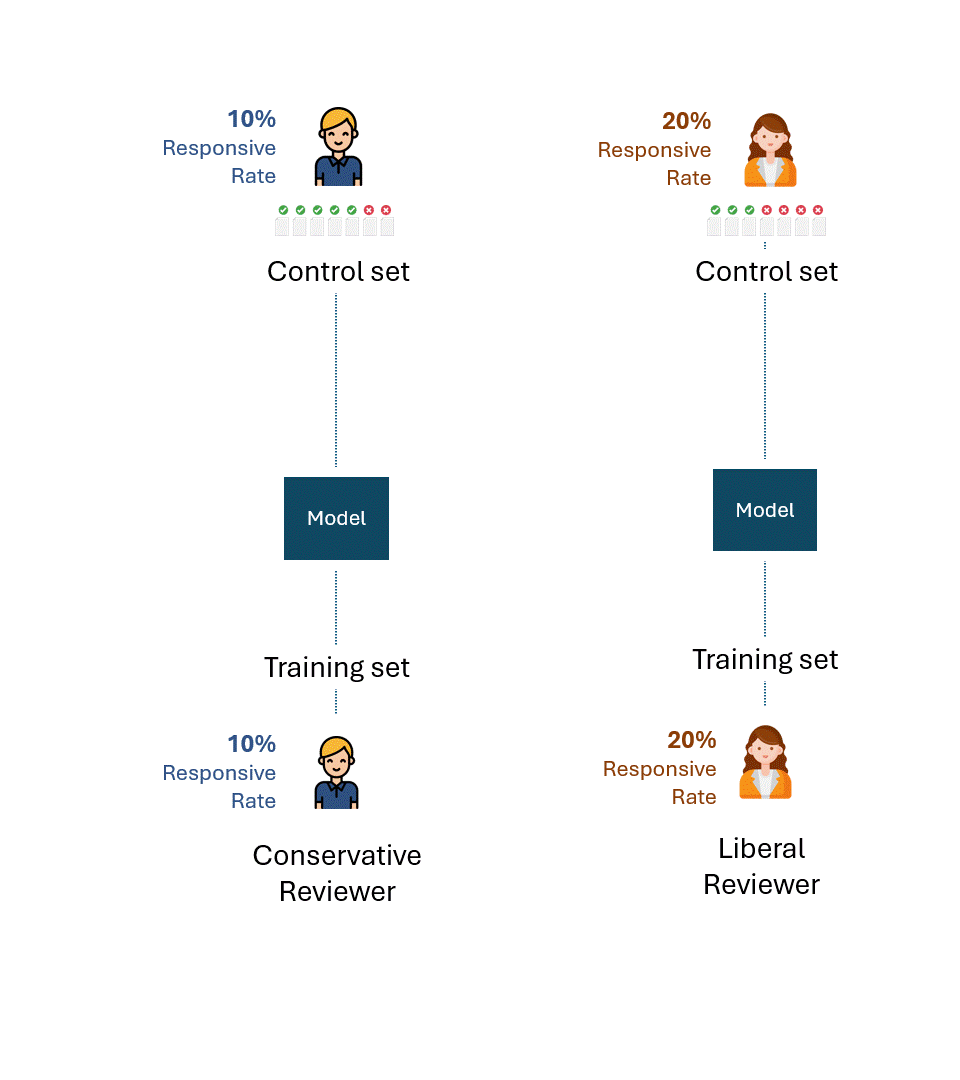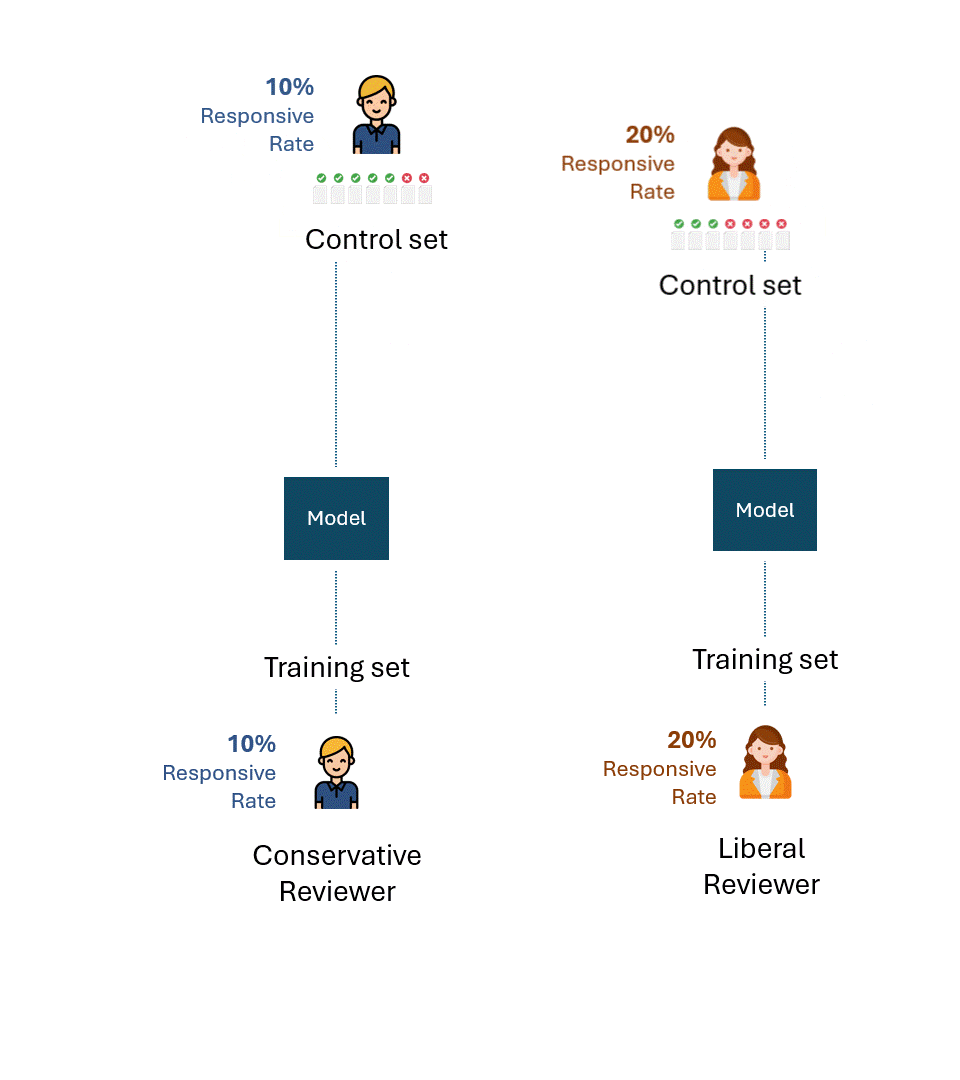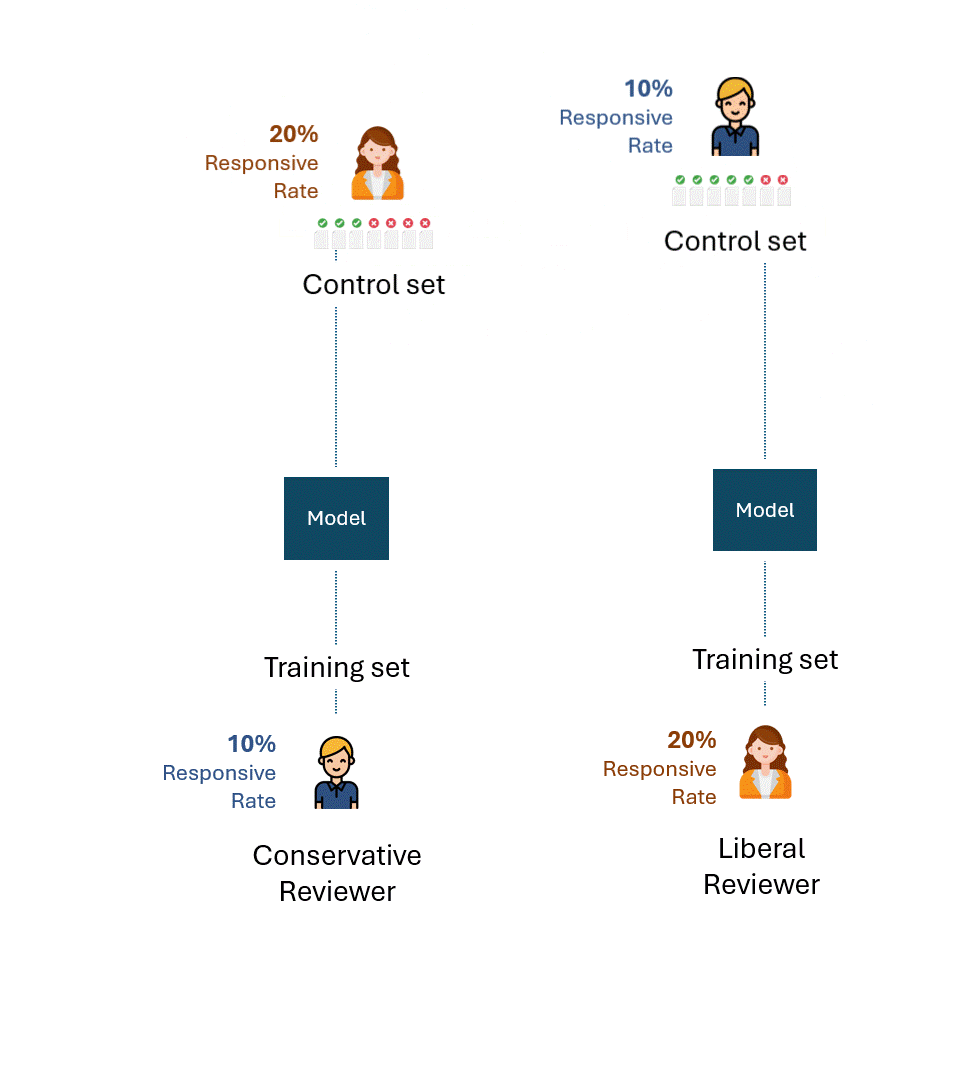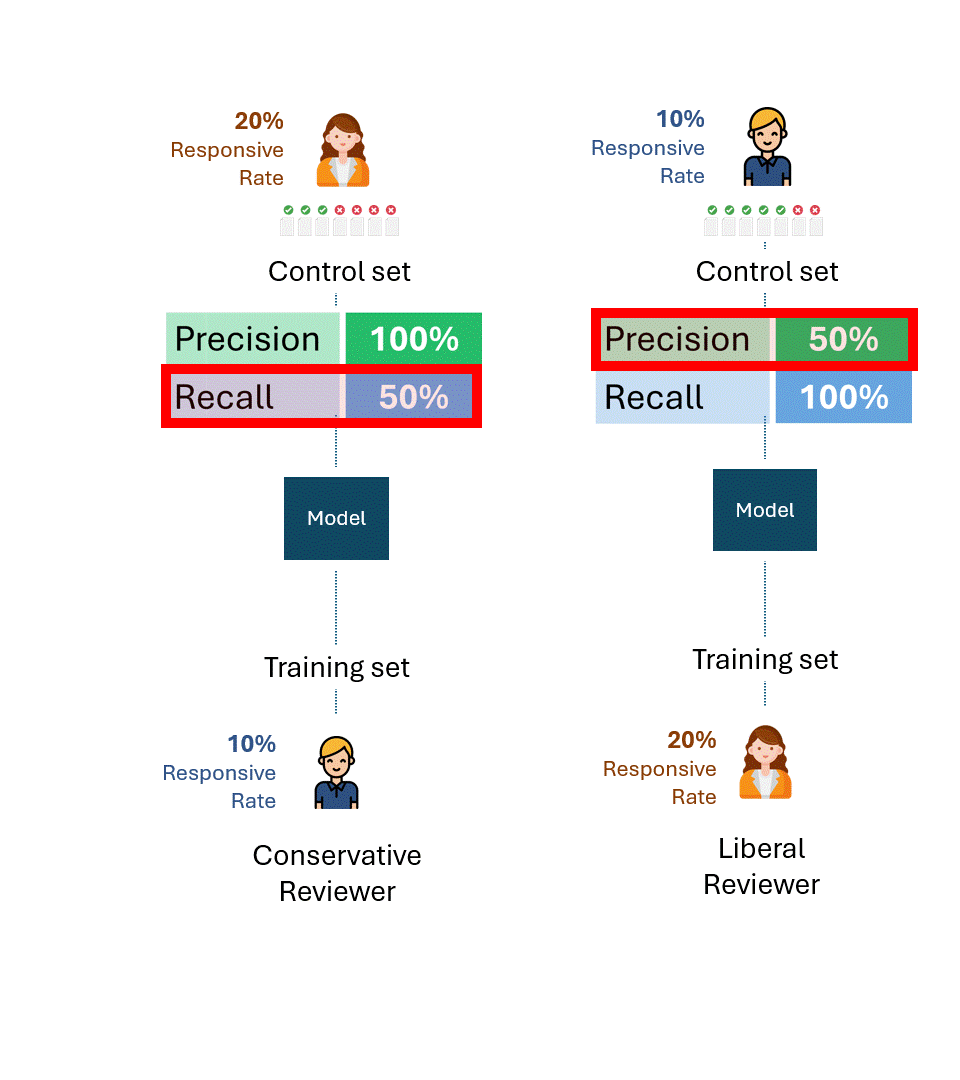
Was ist nun die beste theoretische Leistung bei jedem Kontrollsatz?
Selbst wenn ein liberaler Prüfer, der den Kontrollsatz mit einer Ansprechrate von 20 % erstellt, und ein konservativer Prüfer mit einer Ansprechrate von 10 % maximal konsistent wären, würden sie nur die Hälfte davon als ansprechend markieren, was einer Abrufrate von 50 % entspricht.
Denken Sie einen Moment über die Auswirkungen dieses Sachverhalts nach. Der konservative Prüfer kann diese Auffindungsrate durch noch so viel Training nicht erhöhen. Wenn der Gutachter, der das Modell trainiert, und der Gutachter, der es testet (d. h. über die Kontrollgruppe), eine grundlegende Diskrepanz in ihrer Antwortrate hätten, könnte die Leistung nicht über 50 % hinausgehen.
Was bedeutet das in der Praxis?
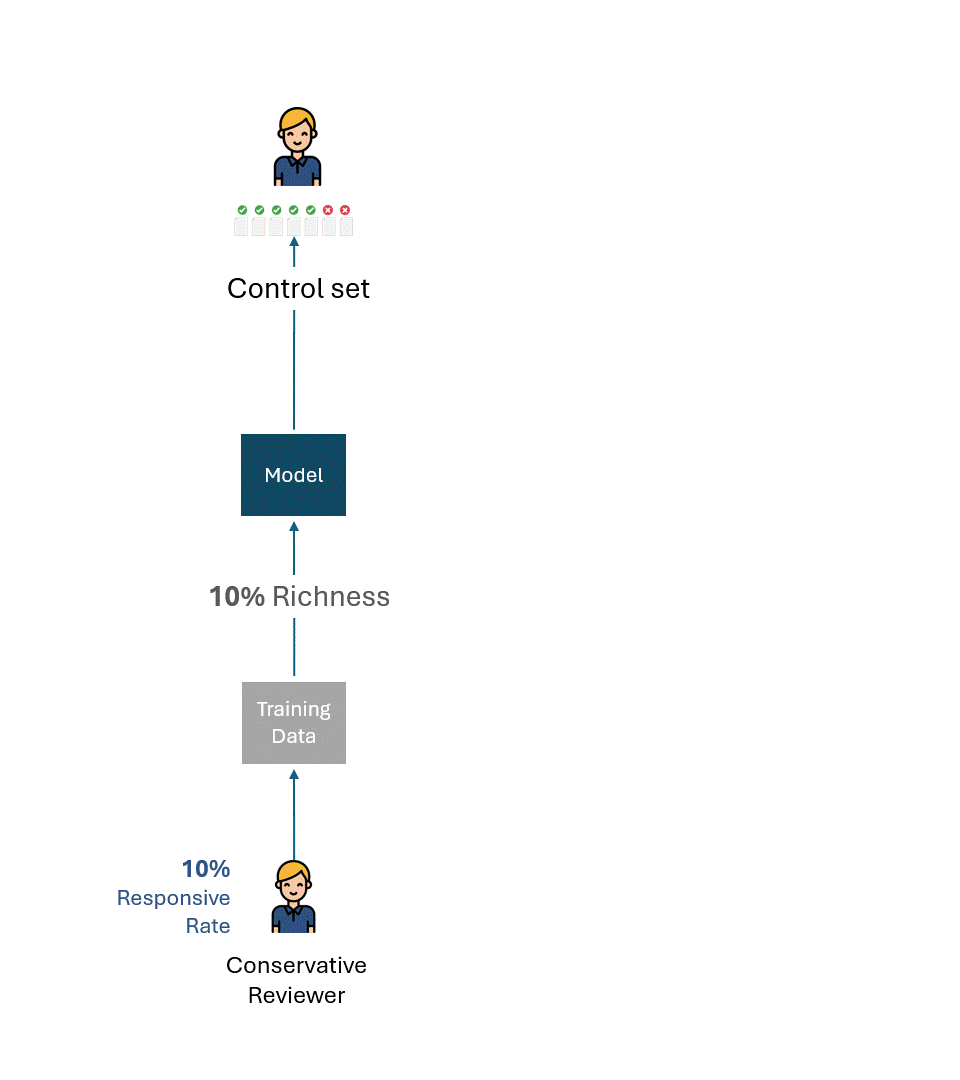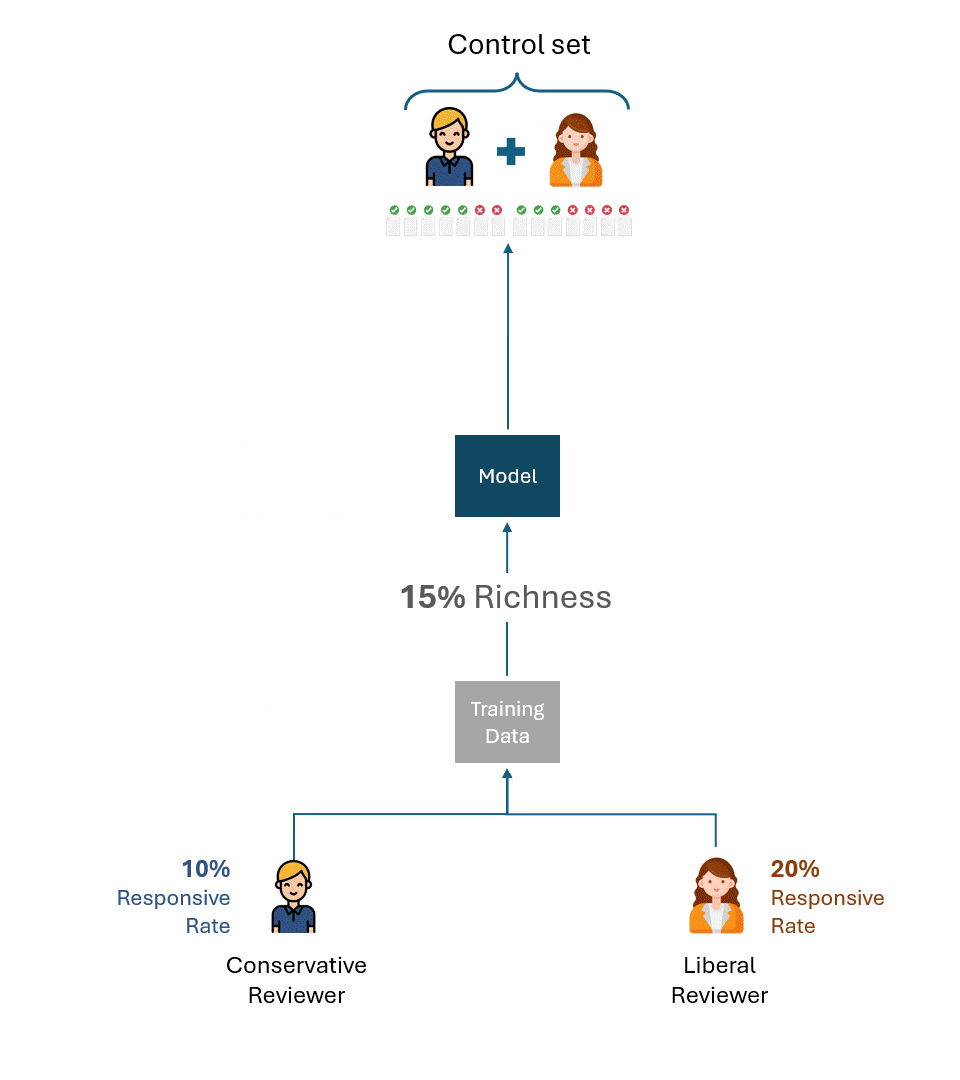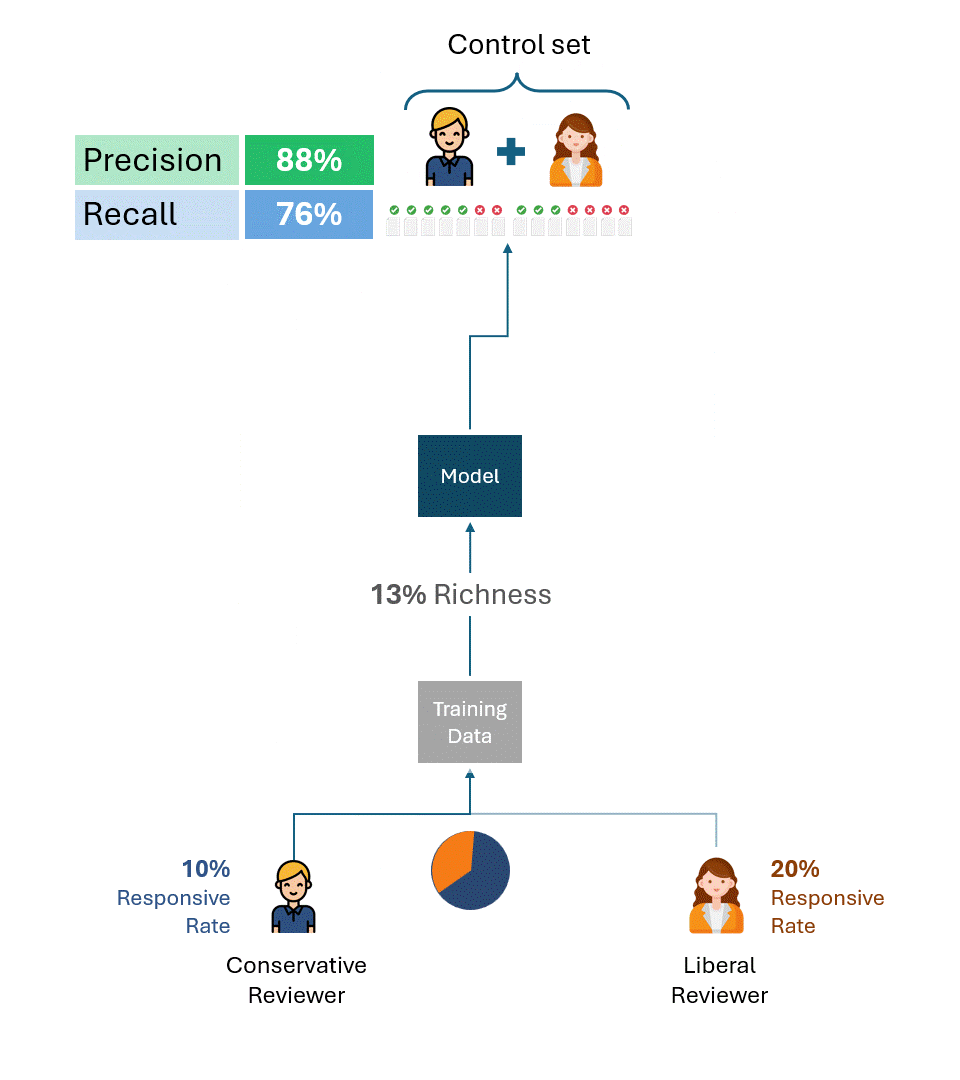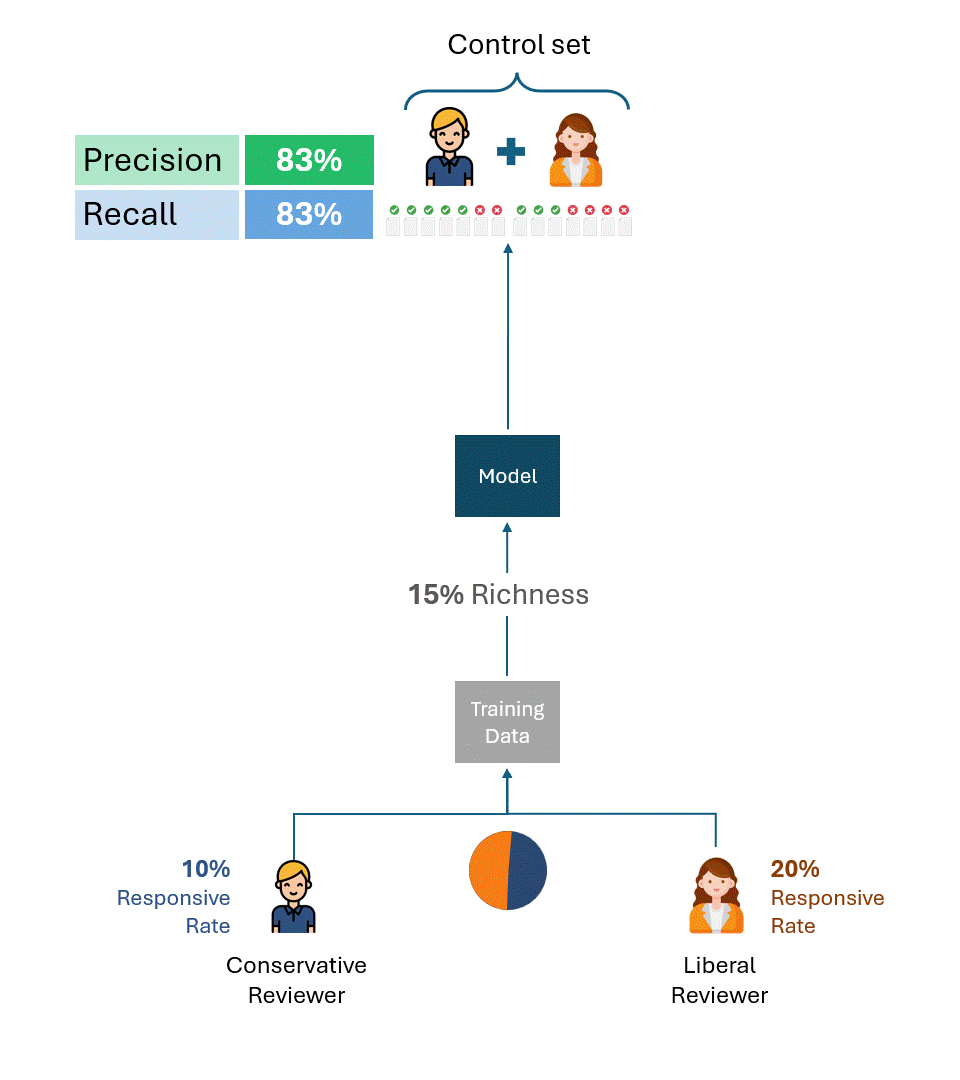
Die obigen Beispiele sind nützlich, um die Ursache des Problems zu verdeutlichen. In der Praxis erstellen jedoch mehrere Prüfer sowohl die Trainingsdaten als auch die Kontrollsätze, wobei die Prüfer oft in unterschiedlichen Anteilen vertreten sind, auch zwischen den Trainingsdaten und den Kontrollsätzen. Dies verkompliziert zwar die Formel zur Berechnung der Leistungsobergrenze, ändert aber nichts am grundlegenden Ergebnis:
Solange die Kontrollgruppe Tags von Gutachtern mit unterschiedlichen Ansprechraten enthält, gibt es eine Leistungsgrenze, die völlig unabhängig vom Modell ist.
Dies gilt unabhängig davon, wie die Trainingsdaten erstellt wurden, ob von nur einem der Gutachter (einem liberalen oder einem konservativen) oder einer proportionalen Kombination aus beiden. Die Leistungshöchstgrenze wird allein durch die unterschiedliche Ansprechrate der Gutachter in der Kontrollgruppe bestimmt.
Das folgende Beispiel veranschaulicht die Leistungsobergrenzen von Modellen, die mit unterschiedlichen Anteilen von Trainingsdaten sowohl konservativer als auch liberaler Gutachter trainiert wurden. Wie Sie sehen können, ist in keinem Szenario eine Leistung von 100 % erzielbar.

Igor Labutov, Vizepräsident, Epiq AI Labs
Igor Labutov ist Vizepräsident bei Epiq und Co-Leiter der Epiq AI Labs. Igor ist Informatiker mit einem starken Interesse an der Entwicklung von Algorithmen für das maschinelle Lernen, die aus der natürlichen Überwachung durch den Menschen lernen, z. B. aus der natürlichen Sprache. Er verfügt über mehr als 10 Jahre Forschungserfahrung in den Bereichen Künstliche Intelligenz und maschinelles Lernen. Labutov promovierte an der Cornell University und war als Post-Doc an der Carnegie Mellon University tätig, wo er bahnbrechende Forschungsarbeiten an der Schnittstelle zwischen menschenzentrierter KI und maschinellem Lernen durchführte. Bevor er zu Epiq kam, war Labutov Mitbegründer von LAER AI, wo er seine Forschungsergebnisse zur Entwicklung neuer Technologien für die Rechtsbranche einsetzte.
Der Inhalt dieses Artikels dient lediglich der allgemeinen Information und stellt keine Rechtsberatung dar.
Subscribe to Future Blog Posts
