
Angle

Warum strukturierte Daten im Zeitalter der KI unerlässlich sind
- Contracts Solutions
Künstliche Intelligenz (KI) verändert die Industrie durch die Automatisierung von Aufgaben und die Gewinnung von Erkenntnissen, aber ihre wahre Wirksamkeit hängt von hochwertigen, relevanten Daten ab. Strukturierte Daten sind der wichtigste Datentyp, um die Vorteile der KI zu maximieren.
Strukturierte vs. unstrukturierte Daten
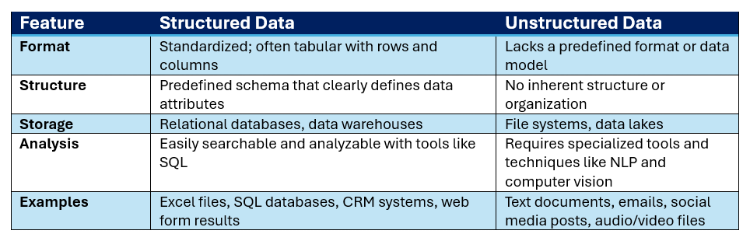
Daten sind je nach Format und Schema, auf dem sie basieren, strukturiert oder unstrukturiert. Ein Schema beschreibt die Organisation und Speicherung von Daten in einer Datenbank und definiert die Beziehung zwischen verschiedenen Tabellen.
Strukturierte Daten haben ein festes Schema, das in Tabellenzeilen und -spalten sortiert ist, z. B. Name, Adresse, Identifikationsnummer, Datum usw. Da strukturierte Daten ein standardisiertes und definiertes Format haben, können Datenanalysetools, Algorithmen für maschinelles Lernen und Benutzer sie einheitlich interpretieren und verwenden. Allerdings ist die Aufbewahrung von Daten in dieser strukturierten Form aufgrund des Pflegeaufwands schwieriger.
Unstrukturierte Daten haben kein festes Schema oder vordefiniertes Format. Sie befinden sich in E-Mails, Kommentaren in sozialen Medien, Audiodateien, Chatprotokollen oder anderen Dokumenten in verschiedenen Repositories und lassen sich nur schwer analysieren und auswerten. Da sie nicht in einem strukturierten universellen Tabellenformat vorliegen, sind unstrukturierte Daten viel flexibler. Die meisten Daten sind jedoch unstrukturiert und liegen unternehmensweit vor, da sie so schnell und einfach erfasst werden können.
Tabelle 1: Strukturierte vs. unstrukturierte Daten
Die Zukunft der Daten in einer KI-geprägten Welt
Trotz des Anstiegs unstrukturierter Daten und der Fortschritte in der KI-Fähigkeit, diese zu verarbeiten, werden strukturierte Daten in der Zukunft der juristischen KI eine immer wichtigere Rolle spielen, da sie in das Contracts Lifecycle Management (CLM) und die Datenmanagementsysteme (DMS) integriert und genutzt werden:
-
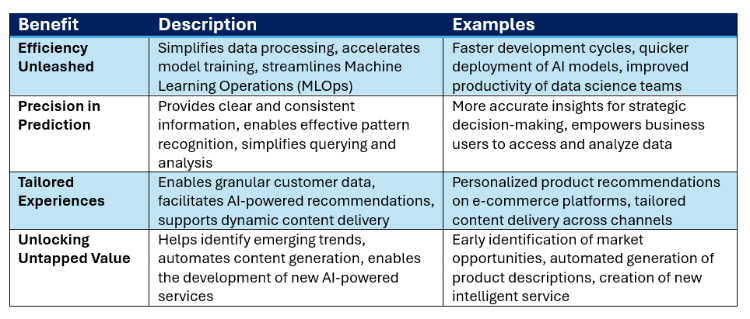
Klarheit und Konsistenz: Die inhärente Klarheit, Konsistenz und Effizienz strukturierter Daten machen sie zu einer entscheidenden Grundlage für den Aufbau zuverlässiger und skalierbarer KI-Systeme.
-
Wissensgraphen: Strukturierte Daten weisen eine Synergie mit Wissensgraphen auf und verbessern die Fähigkeit der KI, den Kontext zu interpretieren und genauere und relevantere Antworten zu geben.
-
Modelle für maschinelles Lernen: Strukturierte Daten sind entscheidend für das Training vieler Arten von Modellen für maschinelles Lernen, insbesondere für Aufgaben wie Klassifizierung, Regression und Vorhersage.
-
Integration mit unstrukturierten Daten: Es gibt einen wachsenden Trend zur Integration strukturierter und unstrukturierter Daten, um umfassendere und aufschlussreichere KI-Anwendungen zu schaffen.
Tabelle 2: Vorteile von strukturierten Daten für KI
Struktur für den KI-Erfolg
Trotz ihrer Vorteile sind strukturierte Daten mit Herausforderungen und Nachteilen verbunden, die Unternehmen angehen müssen, um ihren Wert für KI zu nutzen.
Zentrale Herausforderungen:
-
Unflexibilität: Die Anpassung an sich ändernde Datenanforderungen und die Erfassung komplexer Datentypen kann ohne erhebliche Änderungen am zugrunde liegenden Schema schwierig sein.
-
Ressourcenintensität: Die Pflege und Skalierung der Infrastruktur für strukturierte Daten kann sehr ressourcenintensiv sein, und die Verwaltung dieser Umgebungen ist mit langfristigen Kosten verbunden.
-
Datensilos: Strukturierte Daten können über verschiedene Systeme und Abteilungen hinweg fragmentiert sein, was zu Datensilos führt, die eine ganzheitliche Sicht für effektive KI-Anwendungen behindern.
-
Real-World Data Fit: Nicht alle Daten aus der realen Welt passen in ein strukturiertes Format, was zum Verlust wertvoller Informationen oder zu einer ineffizienten Modellierung führen kann. Hybride Ansätze können erforderlich sein.
-
Vordefinierte Datenmodelle: Die starre Natur strukturierter Daten kann die Anpassung an neue Geschäftsanforderungen ohne wesentliche Anpassungen erschweren.
Data Governance ist entscheidend für die Gewährleistung von Datenqualität, -konsistenz und -sicherheit, die die Grundlage für zuverlässige KI-Anwendungen bilden. Unternehmen müssen die Kosten für die Strukturierung, Speicherung und Pflege strukturierter Daten für KI berücksichtigen. Die Planung eines Datenmodells, das diese Herausforderungen berücksichtigt, trägt dazu bei, dass Ihr Unternehmen flexibel und bereit ist, sich mit den sich ständig verändernden KI-Tools weiterzuentwickeln.

Karthik Radhakrishnan ist Leiter der CLM-Forschung und Entwicklung und Chefarchitekt bei Epiq. Er ist ein erfahrener Technologieführer mit über 35 Jahren IT-Erfahrung, der sich auf die Konzeption, Entwicklung und das Management von Softwareanwendungen spezialisiert hat. Mit über 20 Jahren Erfahrung in den Bereichen Contract Lifecycle Management (CLM) und Configure, Price, Quote (CPQ) liefert er seinen Kunden stets hochwertige Lösungen.
Der Inhalt dieses Artikels dient lediglich der allgemeinen Information und stellt keine Rechtsberatung dar.
Subscribe to Future Blog Posts
