
Angle

AIの時代に構造化データが不可欠な理由
- Contracts Solutions
人工知能(AI)はタスクを自動化し、洞察を生み出すことで産業を変革しているが、その真の効果は高品質で関連性の高いデータにかかっている。構造化データは、AIの利点を最大化するために最も重要なデータタイプである。
構造化データと非構造化データ
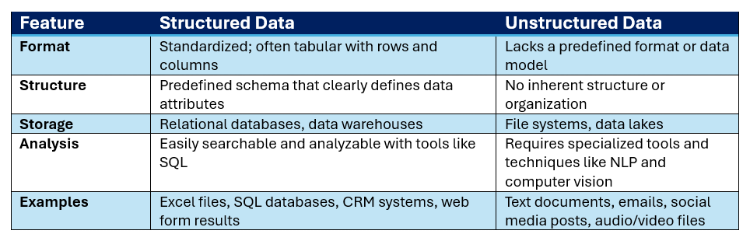
構造化データと非構造化データ データは、そのフォーマットとスキーマによって構造化されたり非構造化されたりする。スキーマとは、データベース内のデータの構成と格納方法を記述し、さまざまなテーブル間の関係を定義するものです。
構造化データには固定されたスキーマがあり、氏名、住所、識別番号、日付など、テーブルの行と列に分類される。構造化データには標準化され定義されたフォーマットがあるため、データ分析ツール、機械学習アルゴリズム、ユーザーはすべて一貫して解釈し使用することができる。しかし、このような構造化された形式でデータを保持することは、それを維持するための労力レベルに基づいて、より厳格になります。
非構造化データには、決まったスキーマや定義済みのフォーマットがない。電子メール、ソーシャルメディア上のコメント、音声ファイル、チャット記録、その他の文書など、さまざまなリポジトリにまたがって存在し、解析や分析が難しい。構造化された普遍的な 表形式ではないため、非構造化データの方がはるかに柔軟性がある。しかし、データの大半は非構造化データであり、非常に迅速かつ容易に収集できるため、企業全体に存在する。
表1:構造化データと非構造化データ
AIファーストの世界におけるデータの未来
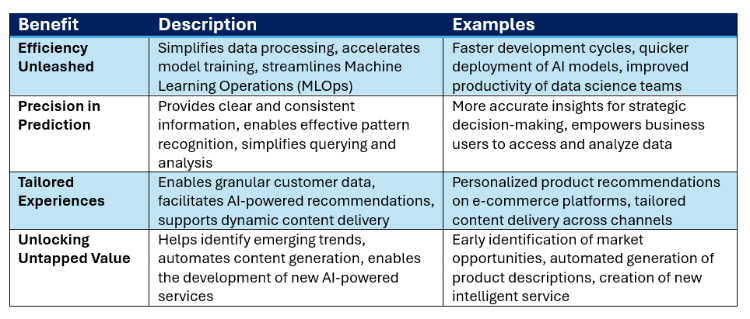
非構造化データの台頭とそれを処理するAIの進歩にもかかわらず、構造化データは、契約ライフサイクル管理(CLM)やデータ管理システム(DMS)に組み込まれ、活用されることで、法務AIの将来においてますます重要な役割を果たすようになる:
-
明快さと一貫性: 構造化データ固有の明快さ、一貫性、効率性は、信頼性が高くスケーラブルなAIシステムを構築するための重要な基盤となっている。
-
ナレッジグラフ: 構造化データはナレッジグラフとの相乗効果を発揮し、AIが文脈を解釈する能力を高め、より正確で適切な応答を提供します。
-
機械学習モデル: 構造化データは、多くの種類の機械学習モデル、特に分類、回帰、予測などのタスクの学習に不可欠です。
-
非構造化データとの統合: 構造化データと非構造化データを統合して、より包括的で洞察に満ちたAIアプリケーションを作成する傾向が高まっている。
表2:AIにおける構造化データの利点
AIの成功のために構造を取り入れる
その利点にもかかわらず、構造化データには課題と欠点があり、組織はAIにその価値を活用するために対処しなければならない。
主な課題
-
柔軟性の欠如: 進化するデータ要件に対応し、複雑なデータタイプをキャプチャするには、基盤となるスキーマを大幅に変更しなければ困難な場合がある。
-
リソースの集中: 構造化データ用のインフラストラクチャの維持と拡張にはリソースが集中し、これらの環境の管理に長期的なコストがかかる可能性がある。
-
データのサイロ化: 構造化データは、異なるシステムや部門にまたがって断片化されている可能性があり、効果的なAIアプリケーションのための全体的なビューを妨げるデータのサイロ化につながる。
-
実世界データとの適合性: すべての実世界データが構造化されたフォーマットに自然に適合するとは限らず、貴重な情報の損失や非効率なモデリングにつながる可能性がある。ハイブリッド。
-
定義済みのデータモデル: 構造化データの硬直的な性質は、大幅な調整なしに新たなビジネスニーズに適応することを困難にする可能性がある。
データガバナンスは、データの品質、一貫性、セキュリティを確保するために極めて重要であり、信頼性の高いAIアプリケーションの基盤を形成する。組織は、AIのために構造化されたデータを構造化し、保存し、維持するコストを考慮しなければならない。これらの課題を理解した上でデータモデルを計画することで、組織は常に変化し続けるAIツールに柔軟に対応し、進化に備えることができる。

Karthik Radhakrishnanは、EpiqのCLM R&D ディレクター兼チーフアーキテクトです。35年以上のIT経験を持つ経験豊富な技術リーダーであり、ソフトウェア アプリケーションの構想、開発、管理を専門としています。契約ライフサイクル管理 (CLM) および構成、価格、見積 (CPQ) の分野で20年以上の専門知識を持ち、一貫して高品質のソリューションを顧客に提供しています。