
Angle

How To Deploy LLMs Part 1: Where Do Your Models Live?
- Legal Transformation
In the early days of first-generation AI models, legal industry technology providers did not frequently encounter the question, “Where do my models live?”
The assumption has always been that the models live where the data lives. If you had an on-premises eDiscovery software license, for example, the models lived “locally” in your data center or cloud instance.
Now, with Large Language Models (LLMs), clients face a new kind of technology with tremendous capabilities and complex challenges. Below, we detail the questions to ask your provider and how to understand their answers regarding the quality and performance of their solution and the security and privacy implications.
Why Ask Now?
“Where does your model live?” is a suddenly prevalent question because these models, specifically LLMs, have outgrown the computational footprints available to most Fortune 100 companies, let alone solution providers themselves. As a result, very few companies have the resources to build and train LLMs. Companies such as OpenAI GPT, Anthropic Claude, and Google Gemini have taken on those massive investments and made their models available via APIs. In the past couple of years, they have spawned thousands of service providers who package that API service as part of their solutions. In legal services, we often see those iterations in document review, document summarization, and contracts review.
The wide availability of third-party services brings significant advantages, but it also raises new questions that we have not previously encountered:
- What information am I sharing with third-party LLMs?
- Is my information stored and used to improve their models?
- Do I have control over those models, and if not, who does?
The list of questions only gets longer as more open-source LLMs become available, which, with the right infrastructure, make it possible to build deployments that do not rely on third-party providers at all. In this case, it becomes important to understand what you would gain and sacrifice in avoiding solutions that rely on third-party service providers.
How Are LLMs Typically Deployed?
There are several deployment options for an LLM service, some of which we may be familiar with and others of which have evolved out of necessity.
In a classical first-generation AI application, such as contracts review or document review, which were primarily classification tasks, the AI models were small enough to live together with your data, whether that be in your own data center or a managed cloud, separate from other clients:
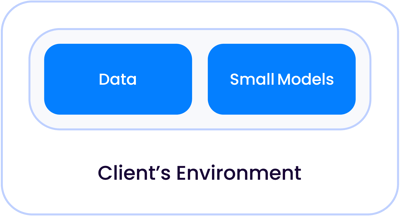
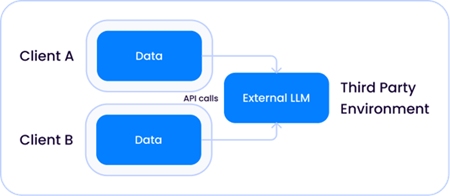
As the model sizes grew exponentially to become what we call LLMs today, there are two instances in which these models can live relative to your data.
1. A shared third-party model hosted by a company such as Open AI, where the LLM is external to both the solution provider and your environments:
2. An LLM hosted and deployed directly by your solution provider, in their cloud environment:

(Service providers incur significant compute and infrastructure costs hosting LLMs and are therefore likely to deploy LLMs as a service shared by their clients.)
Given this primer on the variety of deployment architectures that exist today, it is natural to ask:
Is there any risk in a solution provider relying on an external API service like OpenAI?
As with everything, the general answer is “It depends” — consider three factors:
1. The extent to which a third party, like OpenAI, retains the data sent to its API.
Service providers will have different policies on how long they retain the data sent to their APIs, and those policies are likely to flow through from the terms of service with their third-party LLM API providers.
For example, Microsoft has a default 30-day retention policy for all data sent to its GPT API; however, solution providers may negotiate exemptions to these terms, and many have obtained a zero-day retention policy.
We recommend that you directly inquire with your solution provider about the retention policy they have in place with the third-party API service provider and if needed, optimize it for your organization.
It is important to distinguish between retention and use of your data. Retention does not imply that the third party can use your data to train its models — under most service agreements, the third party cannot use your data.
2. The nature and quantity of the data sent.
The nature and quantity of the data is entirely application-specific. For example, a solution that only uses an external API on public data, such as public court filings, would pose a different risk profile than a solution that sends a client’s discovery data to the API. Drilling down further, different solution providers may send drastically different volumes of sensitive data to the API within discovery applications. For example, solutions that perform targeted question-answering of data would typically send at most a dozen snippets of documents retrieved through a search engine to an external API. In contrast, solutions relying on the third-party API to classify documents would send millions of documents.
3. Third-party Terms of Service on what they can do with your data.
Finally, it’s important to understand that as the number of third-party API providers for LLMs grows, not all are created equal regarding what they can do with the data sent to them. For example, GPT-4 API provided directly by OpenAI can explicitly use your data to improve their models, while the same GPT-4 model provided through Microsoft Azure cannot. It is important to ask your solution provider about the terms of service of their external API service and what specifically they can and cannot do with your data.
What about solution providers that deploy their own LLM models? Are there risks there?
When the solution provider deploys an LLM (typically based on one of the open-source models available, such as Llama-3), they have direct control over data retention and use. As mentioned earlier, an LLM deployed by a solution provider often requires heavy computational resources — and significant financial expenditure – and, therefore, a very likely shared architecture:
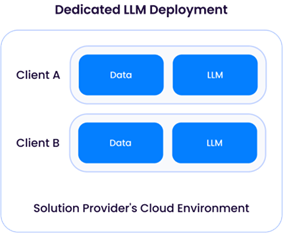
A “Dedicated LLM Deployment” requires a solution provider to provision compute (CPU/GPU/memory) resources to only one client. This would imply renting sufficient GPU resources from a cloud provider, resulting in higher operating costs. The advantage of this approach is the flexibility of the solution provider to customize the LLM to each client by using their data to improve the model without mixing it with data from other clients:
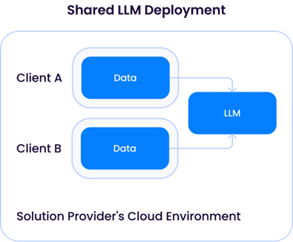
The shared LLM model, however, would raise similar issues as in the third-party LLM service provider instance outlined earlier. While it may seem concerning at first glance, as long as data from different clients is not used to update the underlying LLM, the architecture would be very similar to that of a third-party API service like OpenAI and (at least theoretically) have the same risk profile.
Learn more about Epiq’s approach to delivering AI solutions, and commitment to responsible AI development.
 Igor Labutov, Vice President, Epiq AI Labs
Igor Labutov, Vice President, Epiq AI Labs
Igor Labutov is a Vice President at Epiq and co-leads Epiq AI Labs. Igor is a computer scientist with a strong interest in developing machine learning algorithms that learn from natural human supervision, such as natural language. He has more than 10 years of research experience in Artificial Intelligence and Machine Learning. Labutov earned his Ph.D. from Cornell and was a post-doctoral researcher at Carnegie Mellon, where he conducted pioneering research at the intersection of human-centered AI and machine learning. Before joining Epiq, Labutov co-founded LAER AI, where he applied his research to develop transformative technology for the legal industry.
The contents of this article are intended to convey general information only and not to provide legal advice or opinions.
