

Your Model Isn’t Failing — Your Data Is
- 3 Mins
Model Performance: Expectation vs. Reality
What is your first instinct when your TAR model performs poorly on a control set?
A commonly held view is that more training data (read: more review effort) would help push the performance in terms of Recall and Precision to where you want it to be — and with enough money and time, close to 100%.
Unfortunately, it may take hundreds of wasted review hours before one realises that the model’s performance is capping out at a far-from-ideal number.
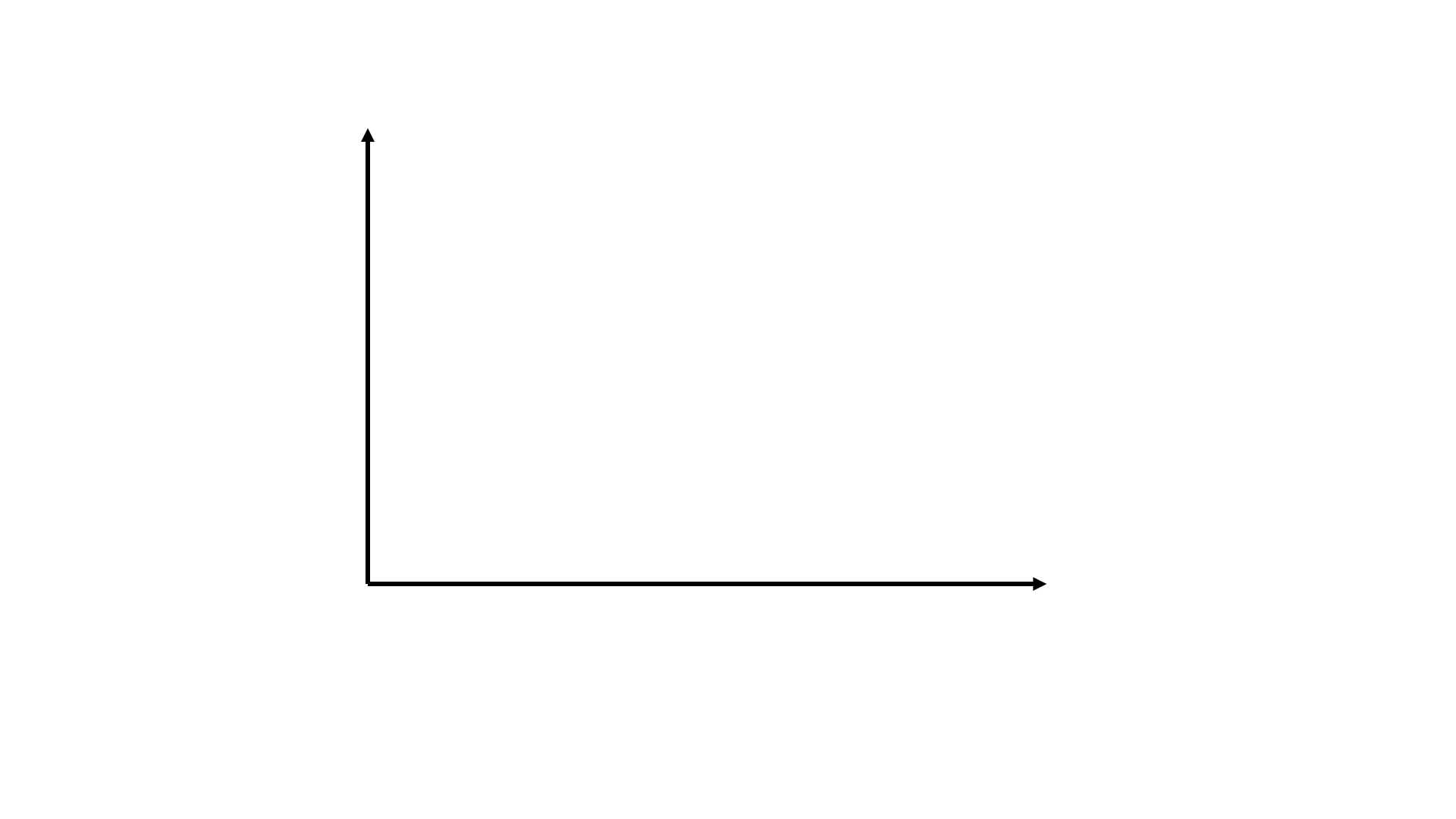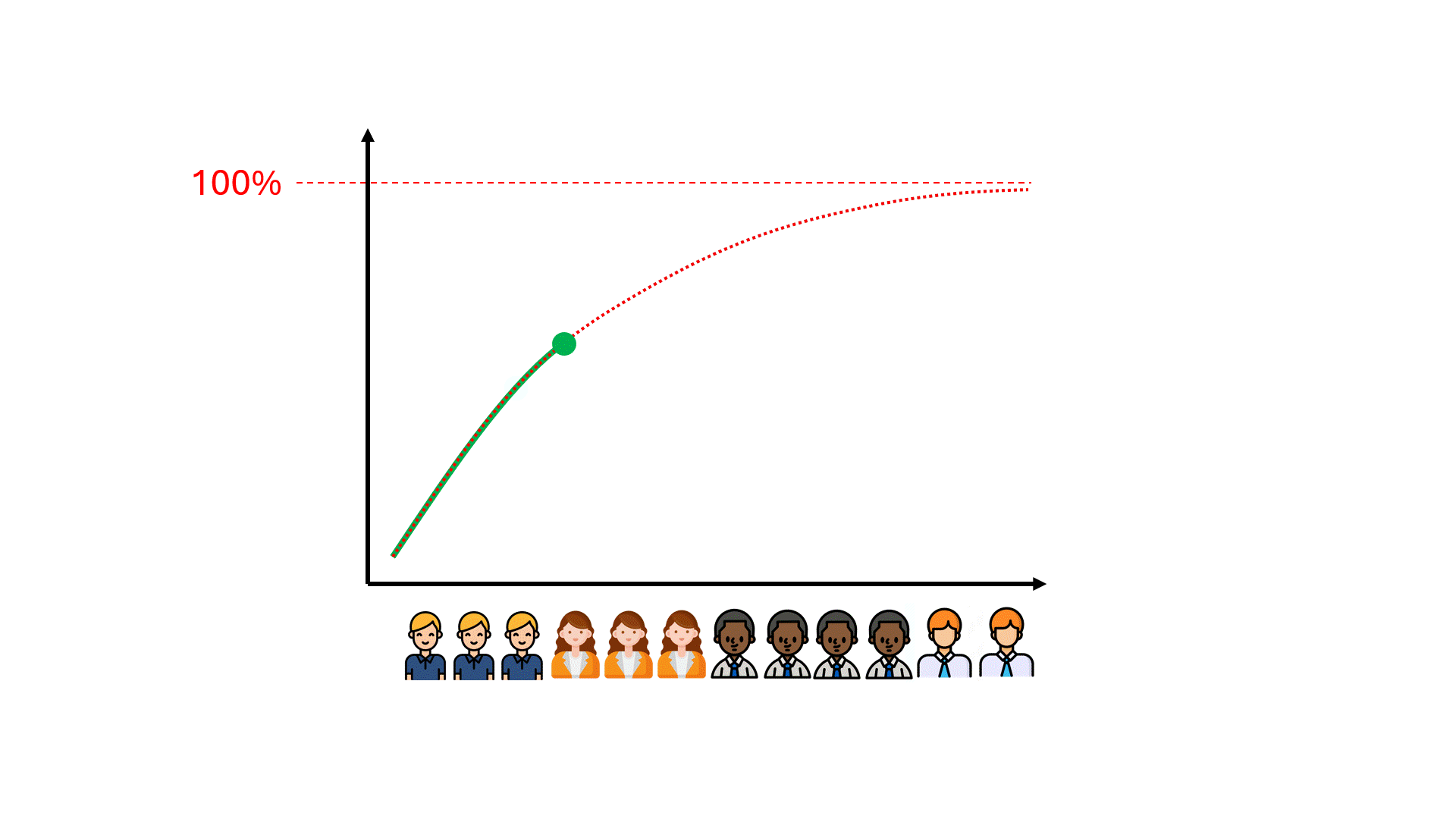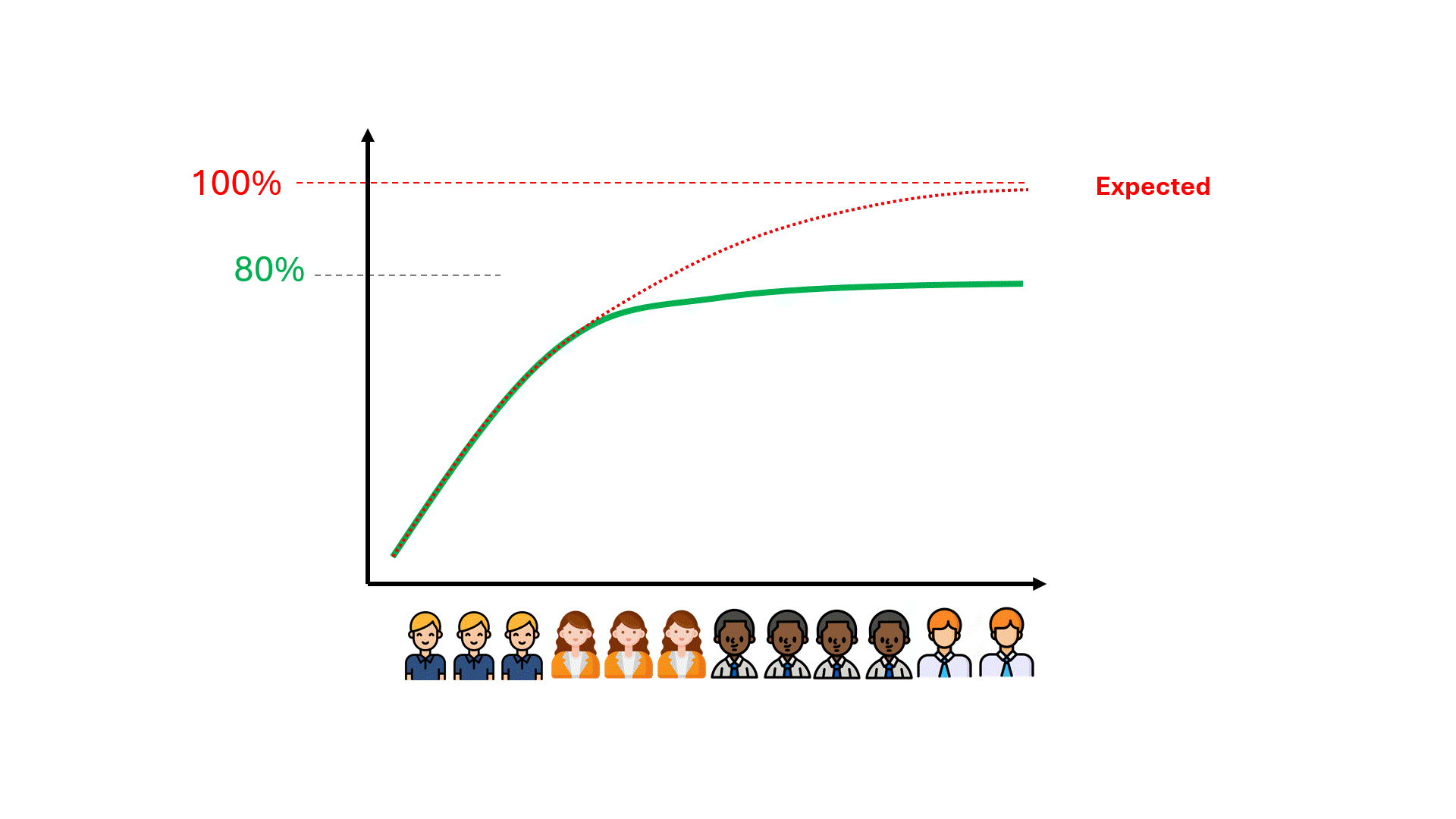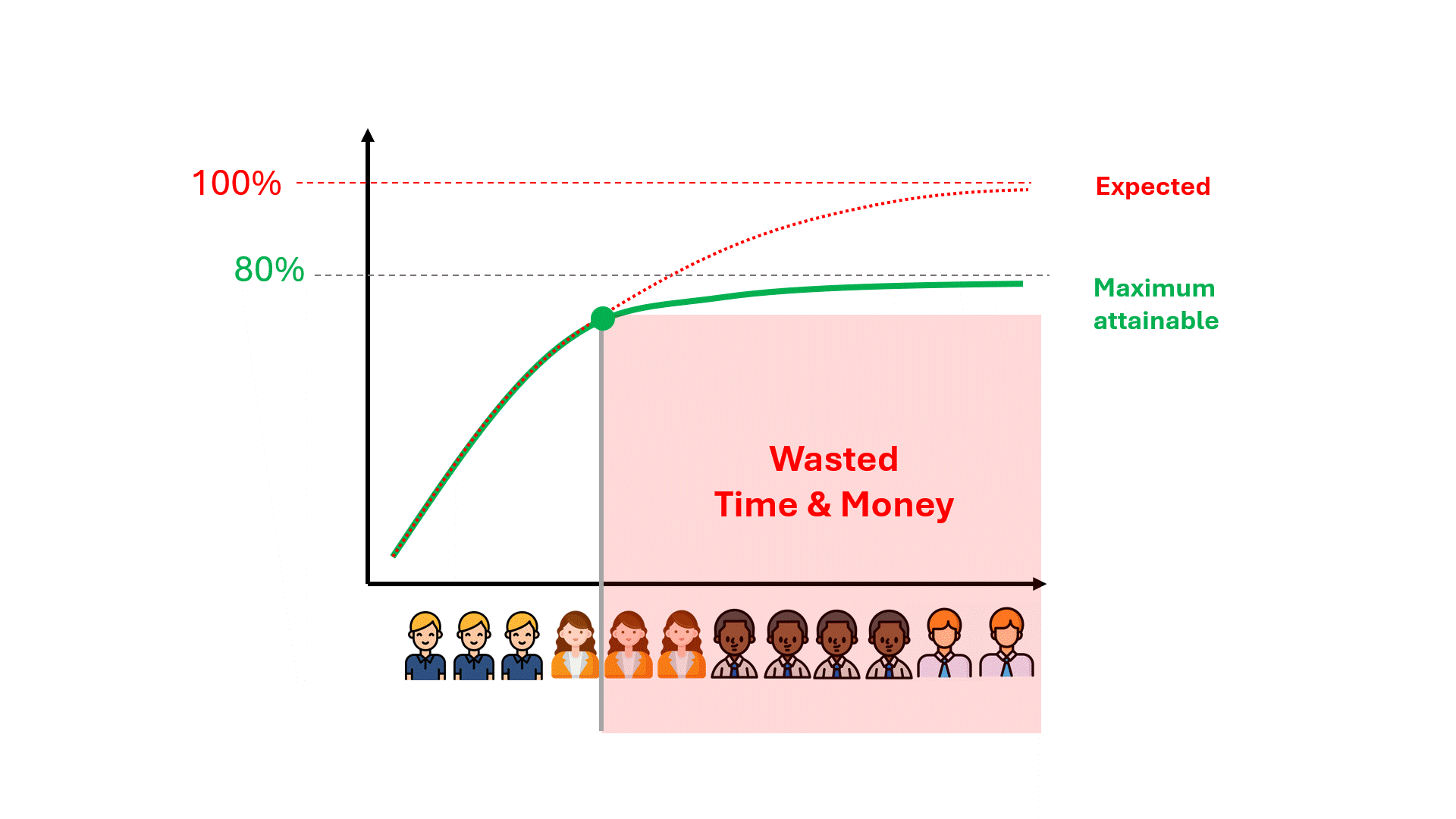
Can we anticipate the ceiling on the model’s performance, potentially saving ourselves time, money, and failed expectations?
Performance Ceiling is Already Encoded in Your Data
Data encodes certain things about the future performance of any model. One of those things is the performance ceiling for metrics such as precision and recall. Whether it be traditional TAR or GPT8, you can pre-compute precision and recall limits, regardless of the model you use, by using the data you already have.
When we say that data already encodes the fundamental limit to your model’s performance, what data are we talking about — training or test data (i.e., control set)?
The reality is that it’s both, but in this article, we will focus on the control set for two key reasons:
-
The control set is entirely model agnostic.
-
It’s possible — through simple math — to compute the performance ceilings.
-
In other words, by analysing the statistics of your control set, we can deduce the best performance for any model, including those that don’t exist today.
What About the Data Leads to Performance Ceilings?
While there could be problems with the original data (e.g., poorly extracted text), we are talking about review tags created by human reviewers in this article. As it turns out, problems with data that lead to performance ceilings boil down to the nature of human review.
It’s entirely sufficient to know just one characteristic about each reviewer to predict the performance ceiling of any model. That characteristic is how liberal or conservative they are in applying review tags. Quantitatively, it’s reflected in their responsive rate or the richness of the data they generate.

To illustrate why this is a critical determinant of the performance ceiling, we will use two prototypical reviewers — a liberal reviewer who is generous in handing out the responsive tag when classifying documents), and a conservative reviewer who is particularly selective in tagging documents. In reality, reviewers are on a spectrum in terms of how they tag, but the illustration of the two extremes will help explain why this phenomenon leads to a performance cap.
Thought Experiment #1
To understand the root of the problem, let’s look at a very simple example.
Imagine that the conservative and the liberal reviewers trained their respective models only on their tags.
Then, suppose that each model was evaluated on control sets comprised only of the respective reviewer’s tags.
Below is a simple visualisation of this process. For illustration purposes, the conservative reviewer has a responsiveness rate of 10%, and the liberal reviewer has a responsiveness rate of 20%.
The question is, what is the best performance possible, i.e., the performance ceiling of each model for each reviewer?
If we take away errors or self-inconsistency of each reviewer, the best possible performance on each control set would, of course, be 100% (100% Recall and 100% Precision):

Thought Experiment #2
Now, let’s imagine a slightly modified situation: the control set for the model trained by the conservative reviewer was created by the liberal reviewer, and vice-versa. In other words, a reviewer other than the one who trained the model created the control set.
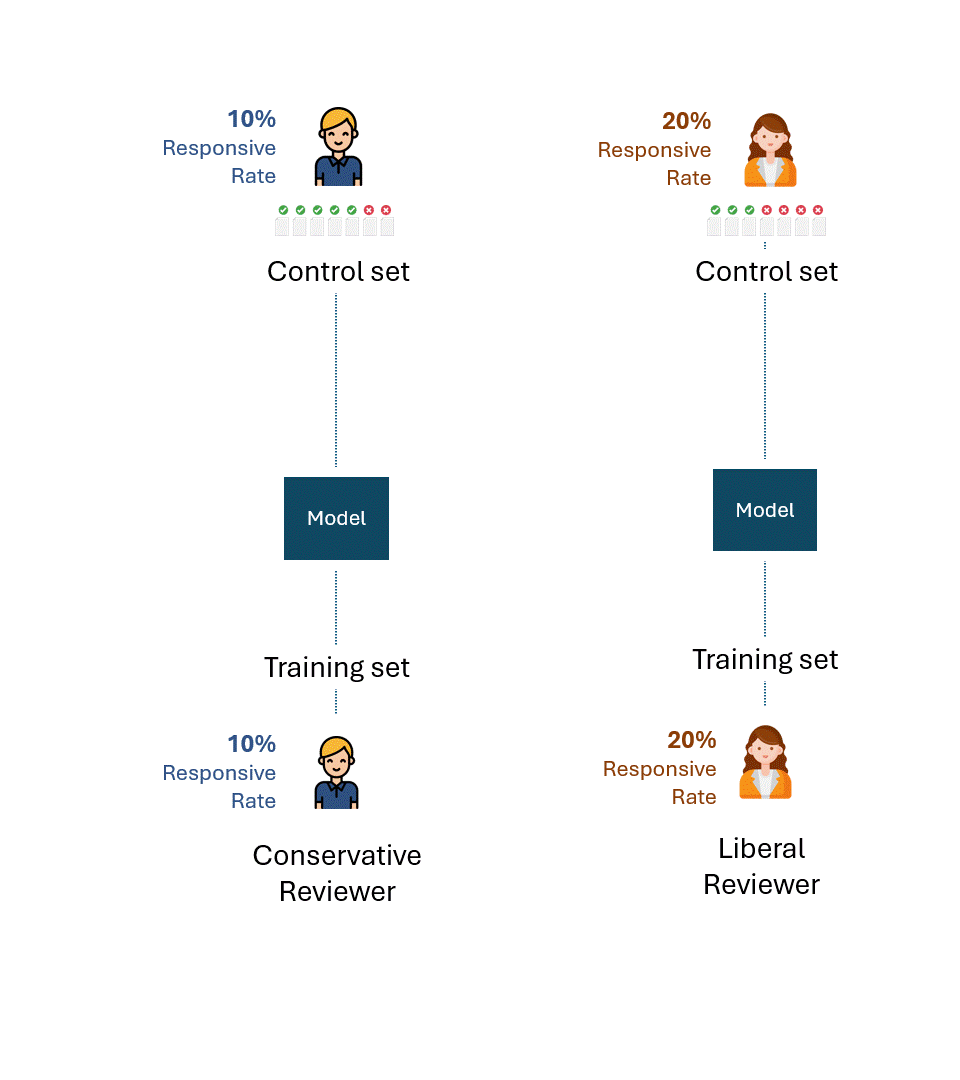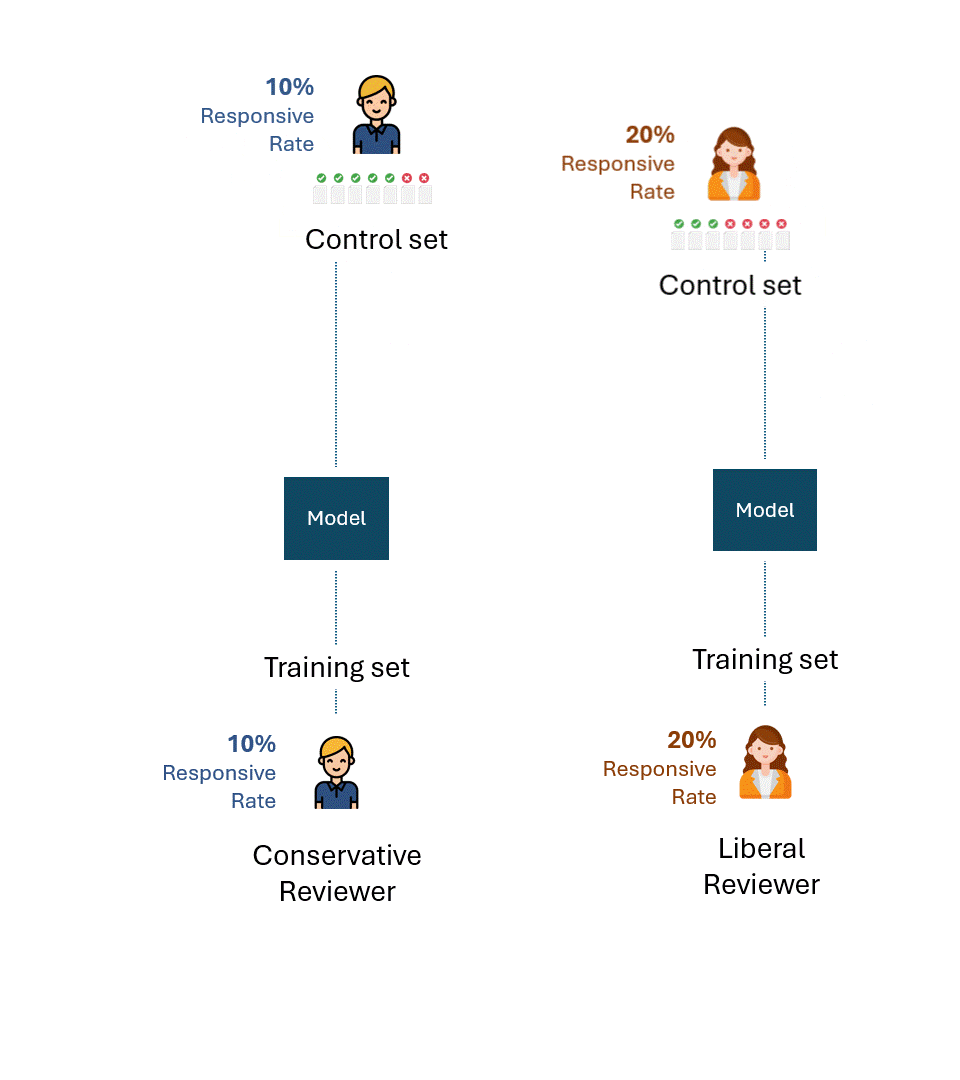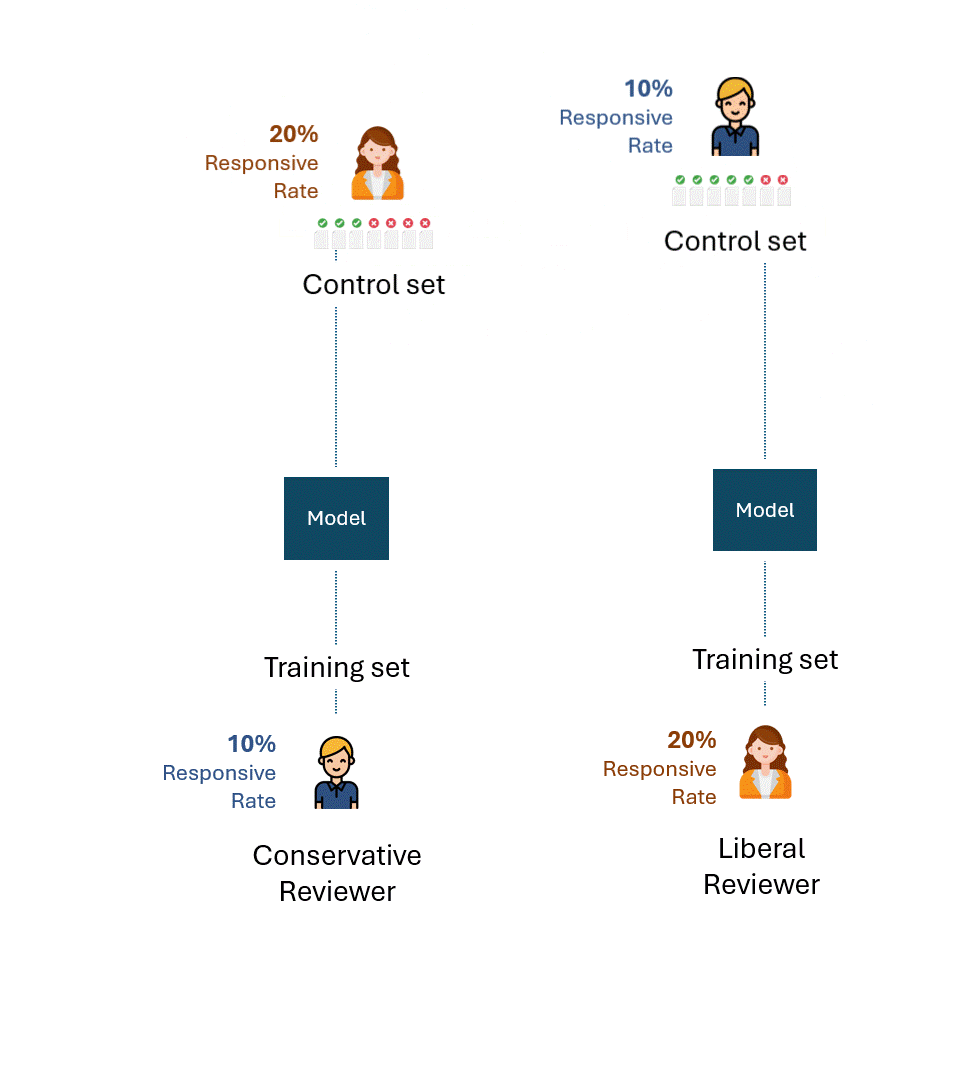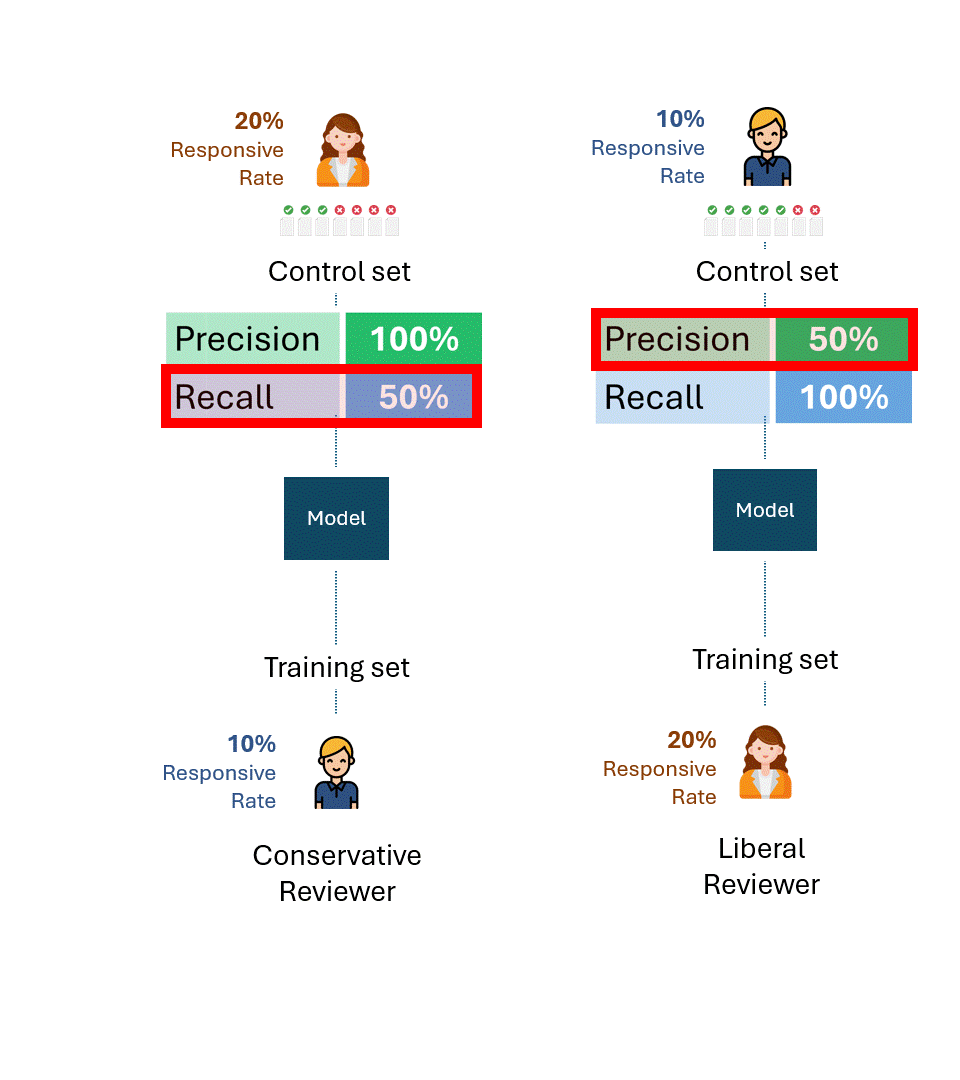
What is the best theoretical performance on each control set now?
Even if a liberal reviewer creating the control set with a responsive rate of 20% and a conservative reviewer with a responsive rate of 10% were maximally consistent, they would only tag half of them as responsive, a recall rate of 50%.
Think about the implications of this for a moment. There is no amount of training that the Conservative reviewer can do to increase that recall rate. If the reviewer training the model and testing it (i.e., via control set) had a fundamental disparity in their responsive rate, the performance could not improve beyond 50%.
What does this mean in practice?
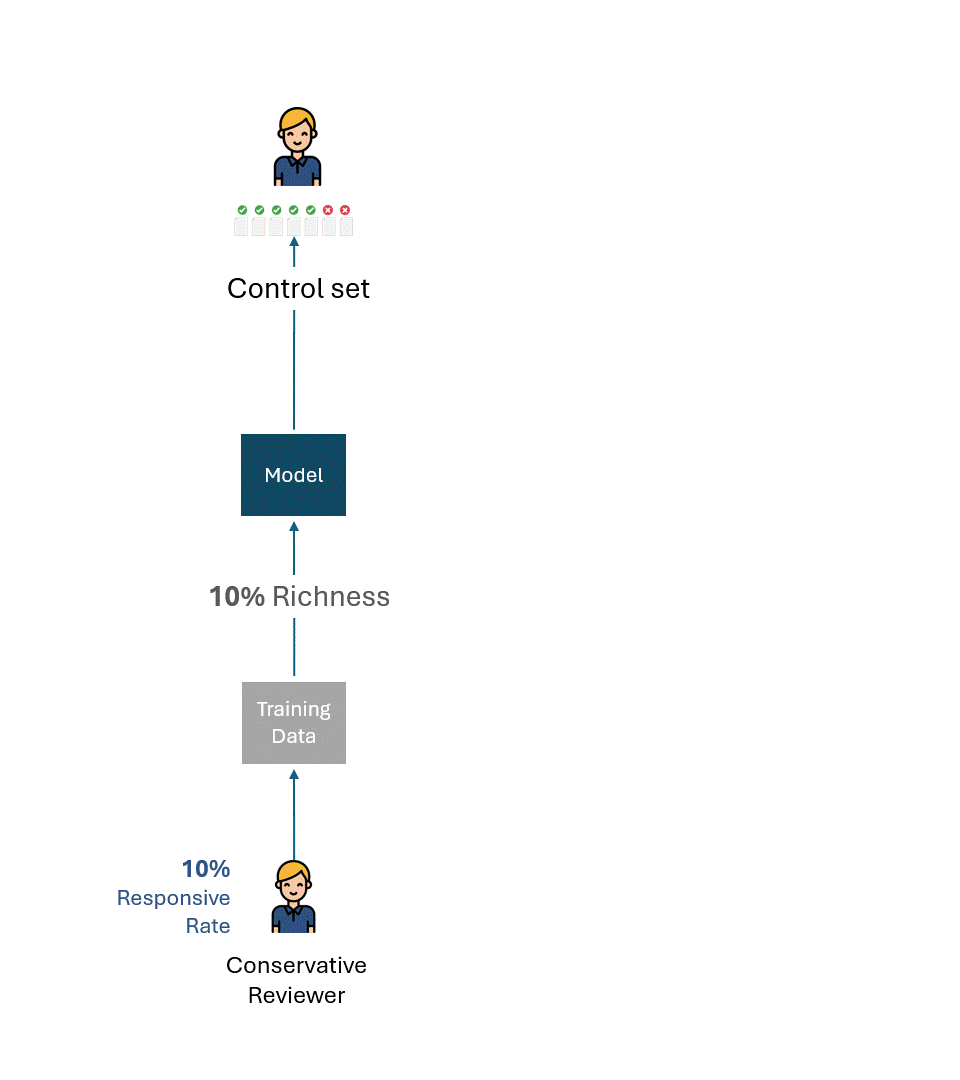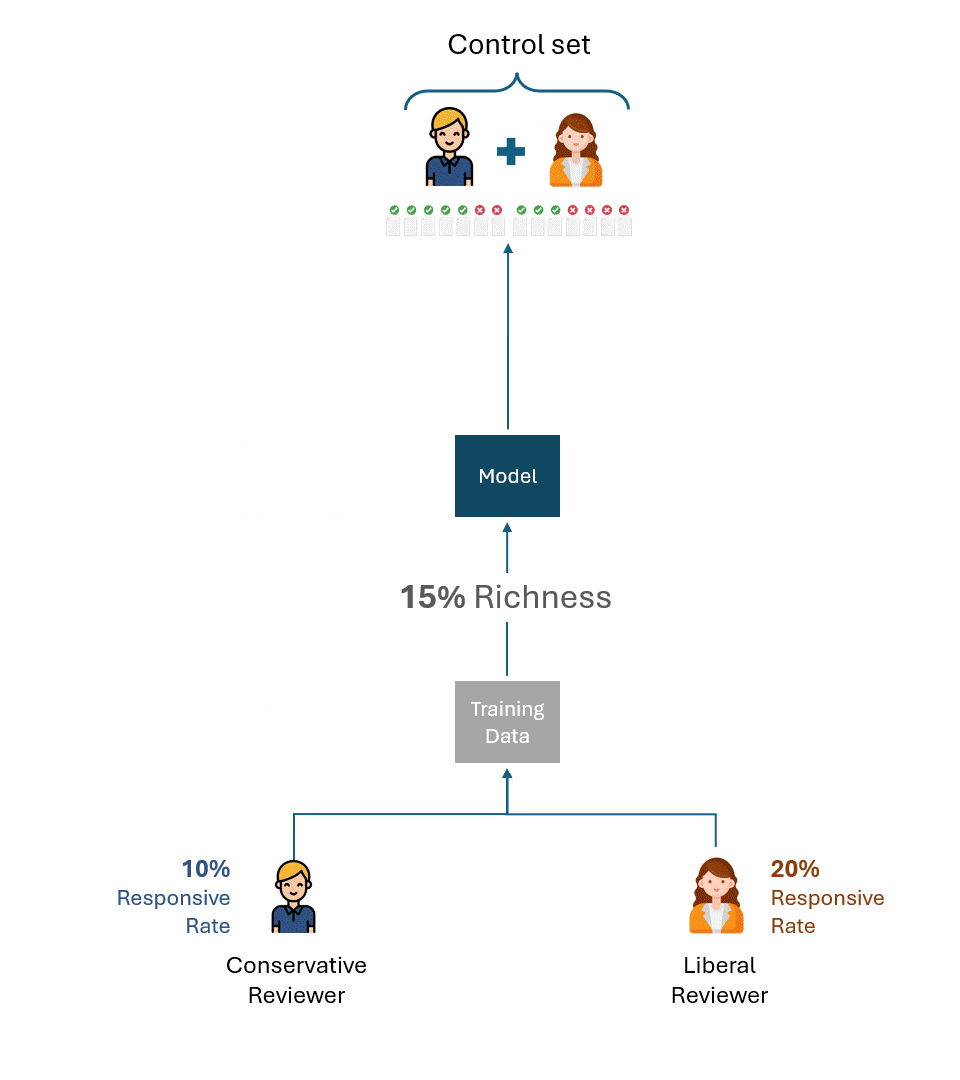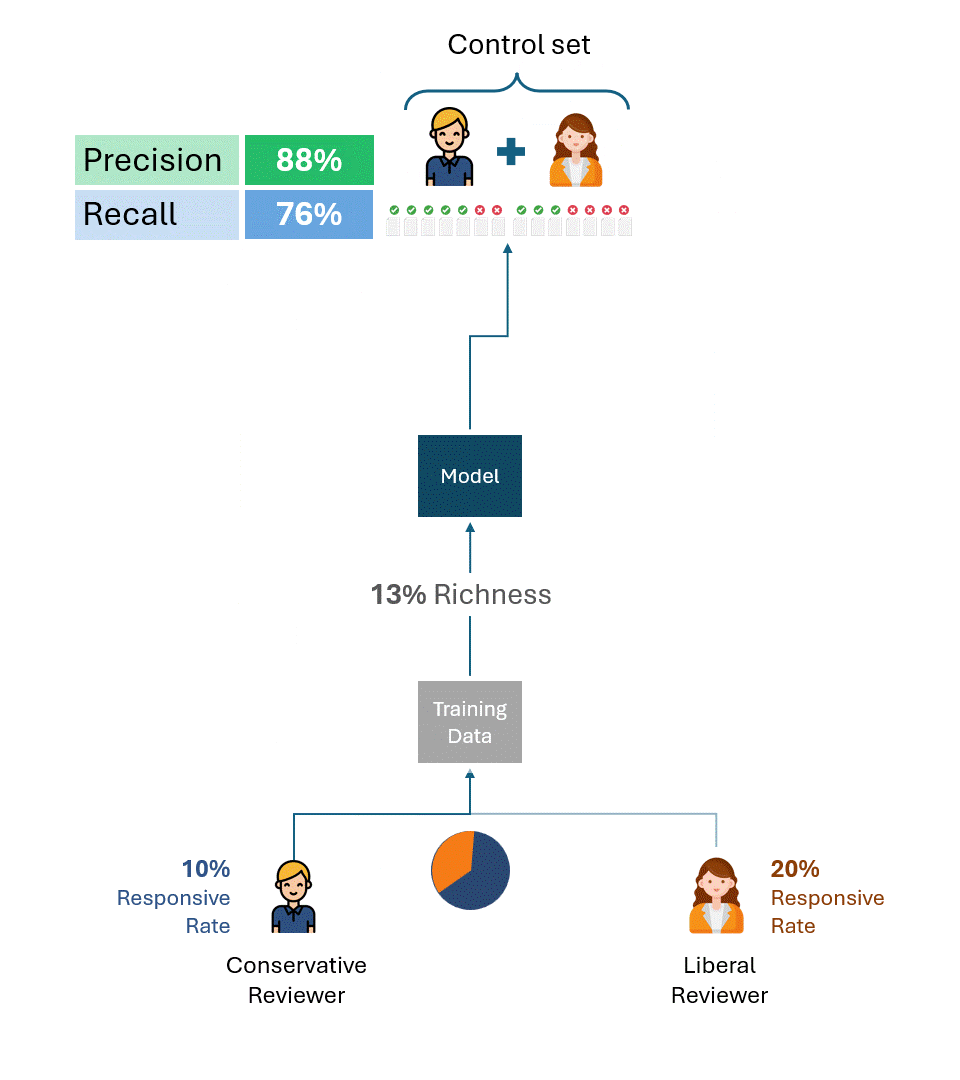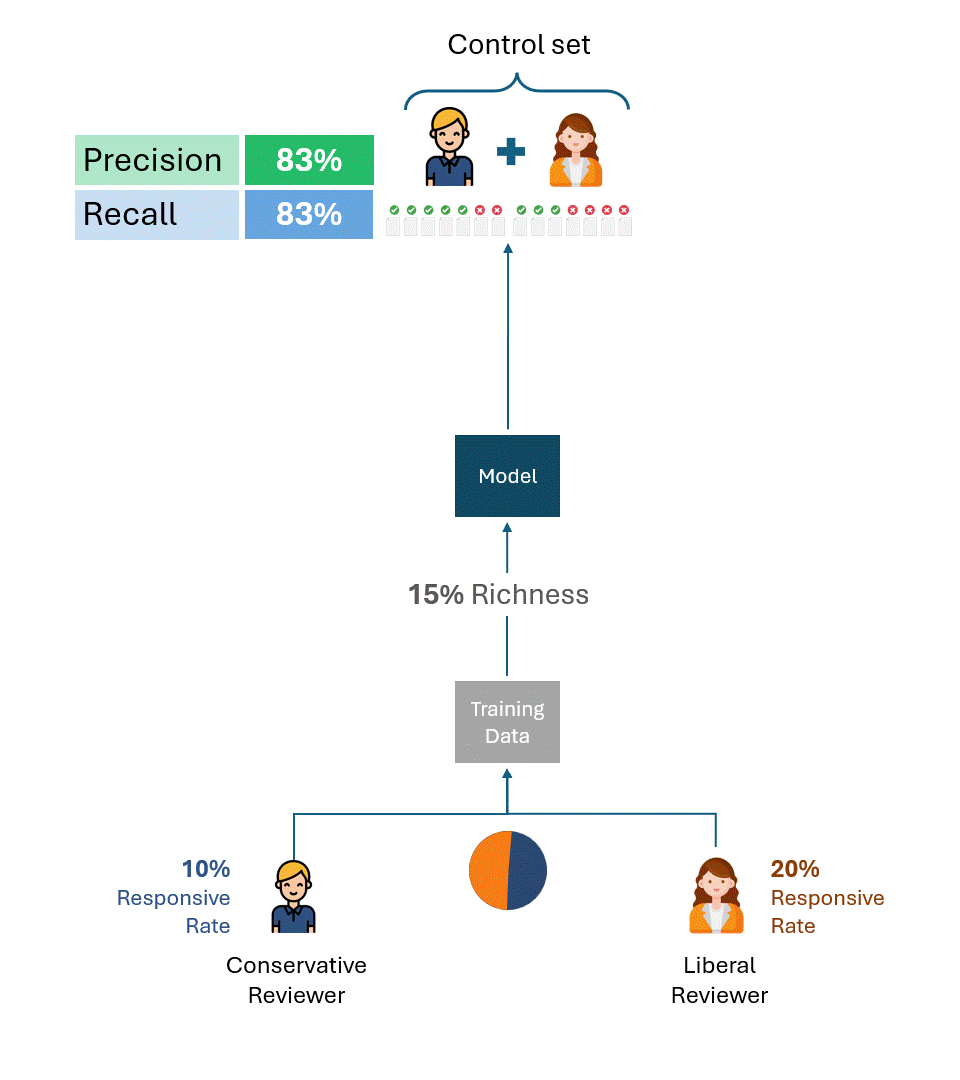
The examples above are useful for illustrating the root cause of the problem. In practice, however, multiple reviewers create both the training data and the control sets, with reviewers often represented in varying proportions, including between the training data and the control sets. While this complicates the formula for computing the performance ceiling, it doesn’t change the fundamental result:
As long as the control set contains tags by reviewers with different responsive rates, there will exist a performance ceiling that is completely independent of the model.
This will hold true regardless of how the training data was created, whether by only one of the reviewers (a liberal or a conservative one) or some proportional combination of the two. The performance ceiling is determined purely by the disparity in the responsive rate of reviewers in the control set only.
Below is an example that illustrates the performance ceilings of models trained using varying proportions of training data from both the conservative and liberal reviewers. As you can see, in no scenario is 100% performance achievable.

Igor Labutov, Vice President, Epiq AI Labs
Igor Labutov is a Vice President at Epiq and co-leads Epiq AI Labs. Igor is a computer scientist with a strong interest in developing machine learning algorithms that learn from natural human supervision, such as natural language. He has more than 10 years of research experience in Artificial Intelligence and Machine Learning. Labutov earned his Ph.D. from Cornell and was a post-doctoral researcher at Carnegie Mellon, where he conducted pioneering research at the intersection of human-centered AI and machine learning. Before joining Epiq, Labutov co-founded LAER AI, where he applied his research to develop transformative technology for the legal industry.
The contents of this article are intended to convey general information only and not to provide legal advice or opinions.